
Limited sample size
Expand sparse structured datasets to test model behavior and reduce brittleness during experimentation.
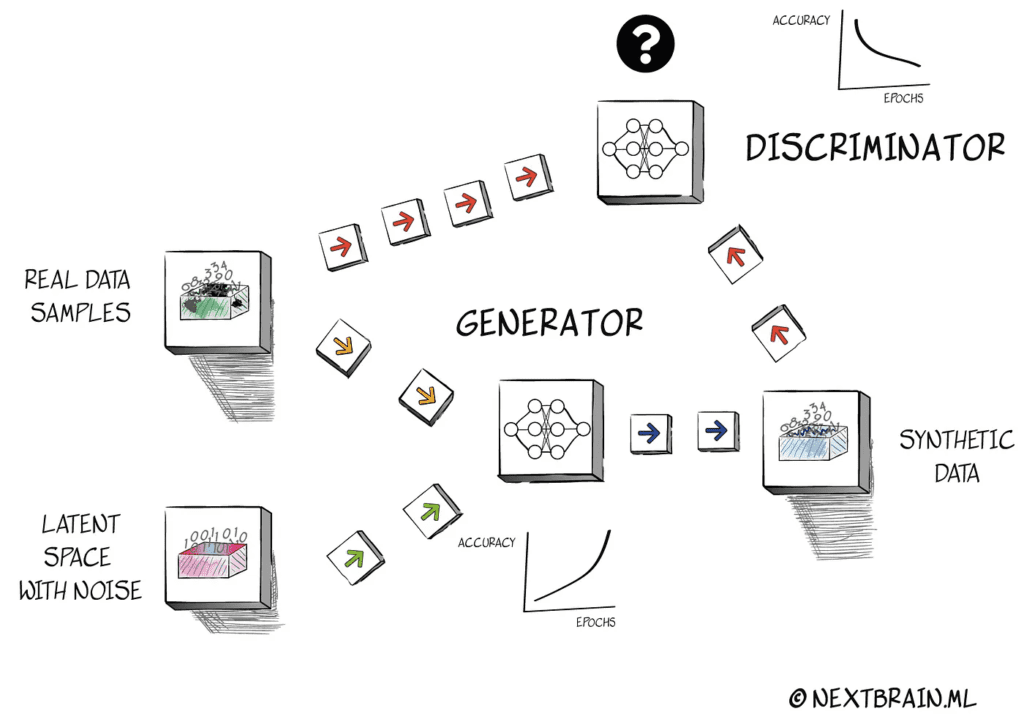
Synthetic data
Synthetic data is useful when real samples are limited, sensitive or uneven. The value is not the generation itself, but whether the synthetic layer actually improves exploration, validation and model stability.
Practical outcome
More robust experimentation for structured machine learning problems where the original sample is too thin for reliable iteration.
Why teams use it
The original page emphasized machine learning value when dataset volume is small. That remains the right framing: synthetic data helps when it supports a clear modeling goal and gets validated properly.
Expand sparse structured datasets to test model behavior and reduce brittleness during experimentation.
Use synthetic generation as part of a broader strategy when access to real data is constrained by governance or exposure risk.
Generate realistic alternative observations to challenge assumptions and inspect how stable downstream models remain.
Validation
A synthetic dataset should be compared against the real one statistically and operationally. Distribution checks, downstream model behavior and scenario-specific testing all matter.
If the synthetic layer drifts too far from the original signal, it can create false confidence. If it is validated well, it can open room for safer experimentation and better data coverage.
Useful checks
Share the problem, the dataset constraints and the decision you need to support. That is the right way to assess whether a synthetic approach makes sense.