
Model coverage
Classical and operational ML workflows in one place
Build, compare and operationalize multiple predictive approaches without splitting the workflow across disconnected tools.
Performance
This page summarizes how NextBrain thinks about performance: practical benchmark design, real model comparison and the operational quality of the workflow around the model.
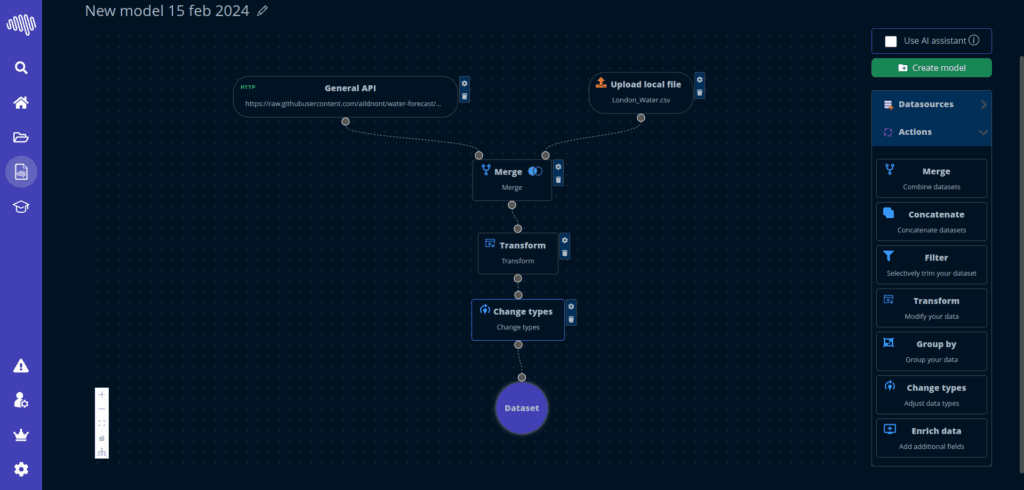
What we compare
Accuracy, workflow friction, explainability and operational readiness.
Why it matters
Benchmarks are useful only when they translate into decisions teams can actually trust.
Comparison logic
The original benchmark page focused on comparing NextBrain against familiar no-code alternatives. The more useful view is broader: how quickly teams can reach a solid model and keep the process usable afterward.
Model coverage
Build, compare and operationalize multiple predictive approaches without splitting the workflow across disconnected tools.
Speed to result
Teams can focus on the decision and the dataset instead of spending most of the time on setup friction and repeated configuration.
Operational usability
Performance only matters when the workflow can actually be understood, reviewed and used by the team that owns the process.
Benchmark framing
A useful AutoML comparison should combine model quality with workflow reality. That means dataset ingestion, feature handling, evaluation clarity, explainability and how easily teams can operationalize the result.
The point is not to optimize for a screenshot benchmark. The point is to make model work faster, clearer and more repeatable across real business scenarios.
Included dimensions
Talk to the team with your dataset, process and target outcome. It is the fastest way to evaluate practical fit instead of abstract feature lists.