
Modellabdeckung
Klassische und operative ML-Workflows an einem Ort
Erstellen, vergleichen und operationalisieren Sie mehrere prädiktive Ansätze, ohne den Workflow auf getrennte Tools zu verteilen.
Performance
Diese Seite fasst zusammen, wie NextBrain uber Performance denkt: praktisches Benchmark-Design, reale Modellvergleiche und die operative Qualitat des Workflows rund um das Modell.
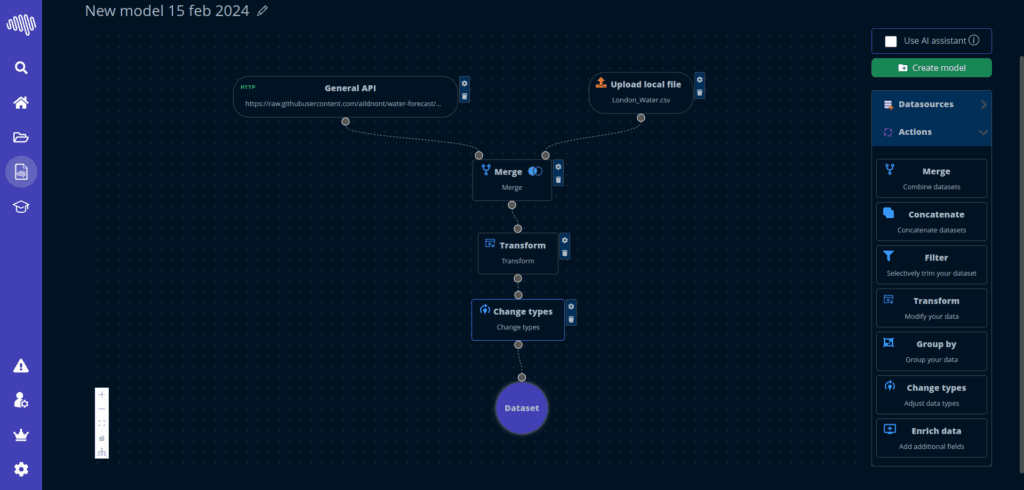
Was wir vergleichen
Genauigkeit, Workflow-Reibung, Erklärbarkeit und operative Reife.
Warum das wichtig ist
Benchmarks sind nur dann nützlich, wenn sie zu Entscheidungen fuhren, denen Teams wirklich vertrauen konnen.
Vergleichslogik
Die ursprüngliche Benchmark-Seite konzentrierte sich auf den Vergleich von NextBrain mit bekannten No-Code-Alternativen. Der nützlichere Blick ist breiter: wie schnell Teams zu einem soliden Modell kommen und den Prozess danach nutzbar halten.
Modellabdeckung
Erstellen, vergleichen und operationalisieren Sie mehrere prädiktive Ansätze, ohne den Workflow auf getrennte Tools zu verteilen.
Zeit bis zum Ergebnis
Teams konnen sich auf Entscheidung und Datensatz konzentrieren, statt den Grossteil der Zeit mit Setup-Reibung und wiederholter Konfiguration zu verbringen.
Operative Nutzbarkeit
Performance zahlt nur dann, wenn der Workflow von dem Team, das den Prozess besitzt, tatsachlich verstanden, geprüft und genutzt werden kann.
Benchmark-Einordnung
Ein nützlicher AutoML-Vergleich muss Modellqualitat mit Workflow-Realitat verbinden. Dazu gehoren Datensatzaufnahme, Feature-Handling, Bewertungs-Klarheit, Erklärbarkeit und wie leicht Teams das Ergebnis in den operativen Betrieb überführen konnen.
Es geht nicht darum, einen Screenshot-Benchmark zu optimieren. Es geht darum, Modellarbeit in realen Business-Szenarien schneller, klarer und wiederholbarer zu machen.
Einbezogene Dimensionen
Sprechen Sie mit dem Team uber Datensatz, Prozess und Zielergebnis. Das ist der schnellste Weg, die praktische Passung statt abstrakter Feature-Listen zu bewerten.