
Begrenzte Stichprobengrosse
Erweitern Sie dünne strukturierte Datensätze, um Modellverhalten zu testen und Instabilitat wahrend der Exploration zu reduzieren.
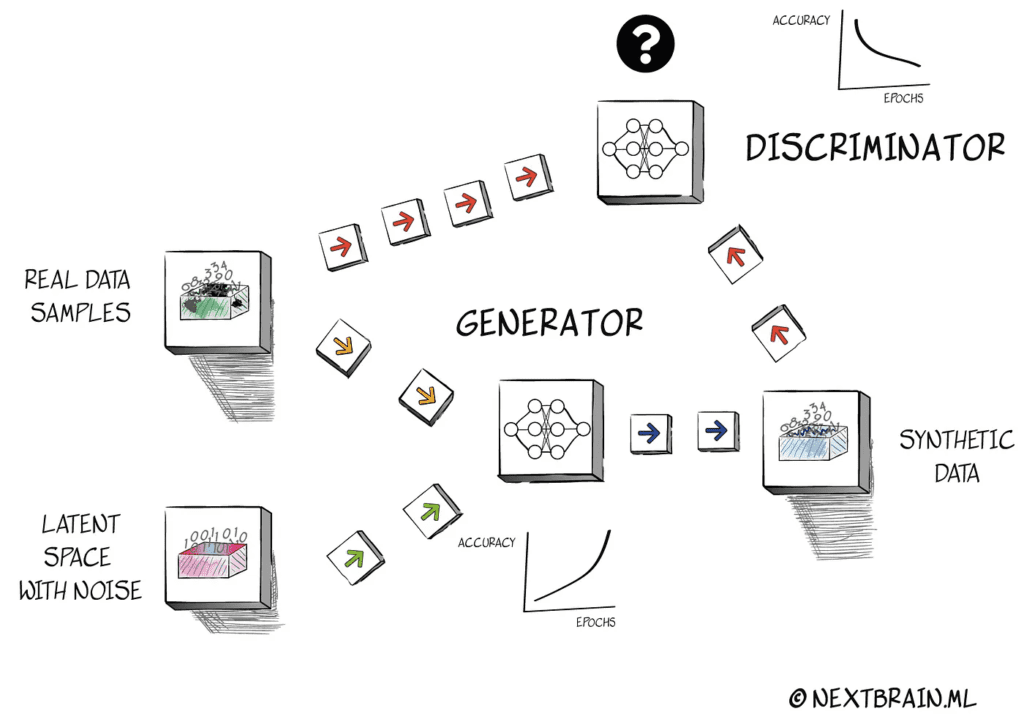
Synthetische Daten
Synthetische Daten sind sinnvoll, wenn echte Beispiele begrenzt, sensibel oder unausgewogen sind. Der Wert liegt nicht in der Generierung selbst, sondern darin, ob die synthetische Ebene Exploration, Validierung und Modellstabilitat tatsachlich verbessert.
Praktisches Ergebnis
Robustere Experimente fur strukturierte Machine-Learning-Probleme, bei denen die Originalstichprobe zu dünn für verlässliche Iteration ist.
Warum Teams das einsetzen
Die ursprüngliche Seite betonte den Wert fur Machine Learning, wenn das Datensatzvolumen zu klein ist. Das bleibt die richtige Einordnung: synthetische Daten helfen dann, wenn sie ein klares Modellierungsziel unterstutzen und sauber validiert werden.
Erweitern Sie dünne strukturierte Datensätze, um Modellverhalten zu testen und Instabilitat wahrend der Exploration zu reduzieren.
Nutzen Sie synthetische Generierung als Teil einer breiteren Strategie, wenn der Zugriff auf reale Daten durch Governance oder Expositionsrisiko eingeschränkt ist.
Erzeugen Sie realistische alternative Beobachtungen, um Annahmen zu hinterfragen und zu prüfen, wie stabil nachgelagerte Modelle bleiben.
Validierung
Ein synthetischer Datensatz sollte statistisch und operativ mit dem realen verglichen werden. Verteilungsprufungen, Verhalten nachgelagerter Modelle und szenariospezifische Tests sind alle relevant.
Wenn sich die synthetische Ebene zu weit vom Originalsiganl entfernt, entsteht falsches Vertrauen. Wenn sie gut validiert ist, schafft sie Raum fur sicherere Experimente und bessere Datendeckung.
Nützliche Prüfungen
Teilen Sie Problem, Datenrestriktionen und die Entscheidung, die Sie unterstutzen mussen. So lasst sich beurteilen, ob ein synthetischer Ansatz sinnvoll ist.