
サンプル数の不足
疎な構造化データセットを拡張し、実験時のモデル挙動を確認して脆さを減らします。
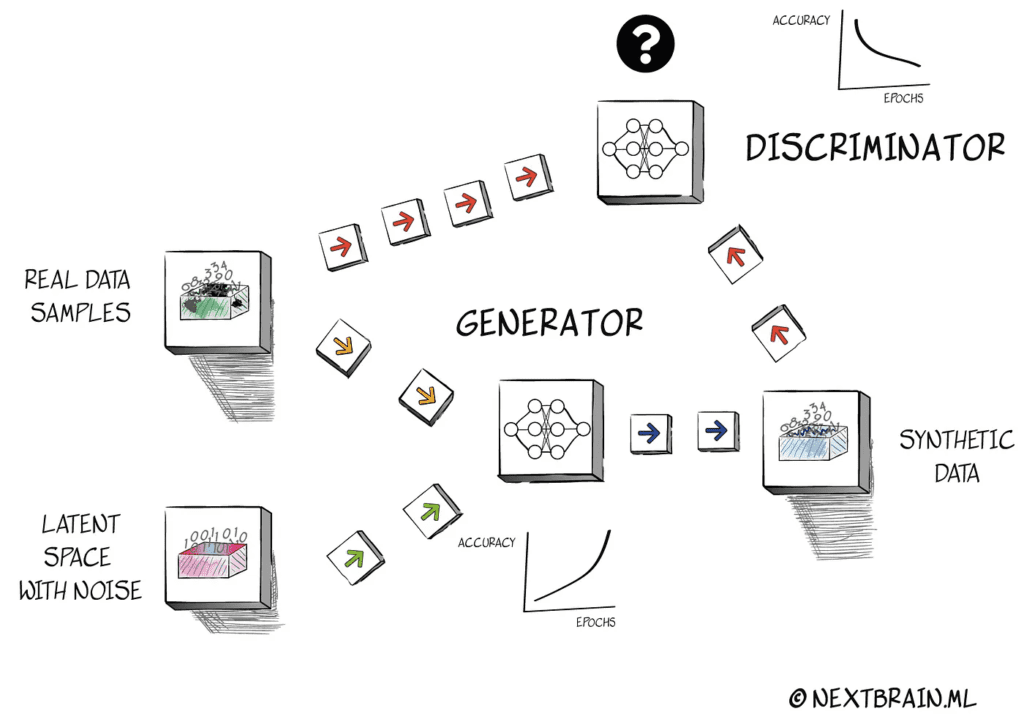
Synthetic data
実データが少ない、機微性が高い、または偏りが大きい場合、合成データは有効です。価値は生成そのものではなく、探索、検証、モデル安定性を実際に改善できるかにあります。
実務上の成果
元サンプルが薄く、信頼できる反復が難しい構造化機械学習課題に対して、より堅牢な実験環境を提供します。
活用される理由
元ページが強調していたのは、データ量が少ないときの機械学習上の価値でした。それは今も正しい見方です。明確なモデリング目的を支え、適切に検証されるときにこそ意味があります。
疎な構造化データセットを拡張し、実験時のモデル挙動を確認して脆さを減らします。
実データへのアクセスがガバナンスや露出リスクで制限される場合、より広いデータ戦略の一部として活用できます。
現実的な代替観測値を生成し、前提を揺さぶり、下流モデルがどれだけ安定しているかを確認できます。
Validation
合成データセットは、統計面と運用面の両方で実データと比較すべきです。分布チェック、下流モデルの挙動、シナリオ別テストのすべてが重要です。
合成レイヤーが元の信号から離れすぎると、誤った安心感を生みます。適切に検証されれば、より安全な実験とデータカバレッジ向上の余地を作れます。
有効なチェック項目