
nbsynthetic : A Simple and Robust Unsupervised Synthetic Tabular Data Generation Python Library
NextBrain.ai presentsnbsynthetic, an open-source project that aims to provide a simple and stable solution for unsupervised synthetic tabular data generation using a Generative Adversarial Network (GAN) architecture based on Keras.
Designed for Simplicity and Robustness nbsynthetic utilizes a straightforward and stable unsupervised GAN architecture built with Keras. The specific hyperparameter tuning ensures training stability while minimizing computational costs.
Advantages of nbsynthetic
The Importance of Tabular Synthetic Data Generation While synthetic data generation has gained popularity in applications like image and speech generation, the development of synthetic tabular data has been less ambitious. However, tabular data is the most common type of data worldwide and has significant implications for industries such as autonomous vehicles, healthcare, and financial services. Synthetic tabular data can address privacy concerns in the healthcare industry, simulate synthetic genomic datasets, and facilitate research projects involving patient medical records.
Empowering Spreadsheet Users Every day, nearly 700 million people use spreadsheets to work with small samples of tabular data. However, these datasets are often considered of poor quality due to incompleteness or lack of statistical significance. Machine Learning techniques, like GANs, can offer valuable insights and decision-making capabilities for such applications. Unfortunately, current ML advancements primarily focus on large datasets, excluding a significant number of potential users who work with small datasets. Additionally, the reliability of ML algorithms applied to small sample size data is a concern in modern statistics.
- No Predefined Target Required: As an unsupervised architecture, nbsynthetic eliminates the need for users to have a predefined target.
- Ideal for Small Datasets: It is primarily intended for small datasets that contain both continuous and categorical features.
- CPU Compatibility: Due to its simplicity, the models can be run on a CPU.
- Convenient Data Preparation: The library includes modules for quick input data preparation and feature engineering.
- Statistical Tests and Comparison: nbsynthetic provides modules for running statistical tests and comparing real and synthetic data, using the Maximum Mean Discrepancy (MMD) statistical test. This test measures the distance between the means of two samples mapped into a reproducing kernel Hilbert space (RKHS).
- Plotting Utilities: Plotting utilities are included for comparing the probability distributions of the original and synthetic data.
A new tabular GAN
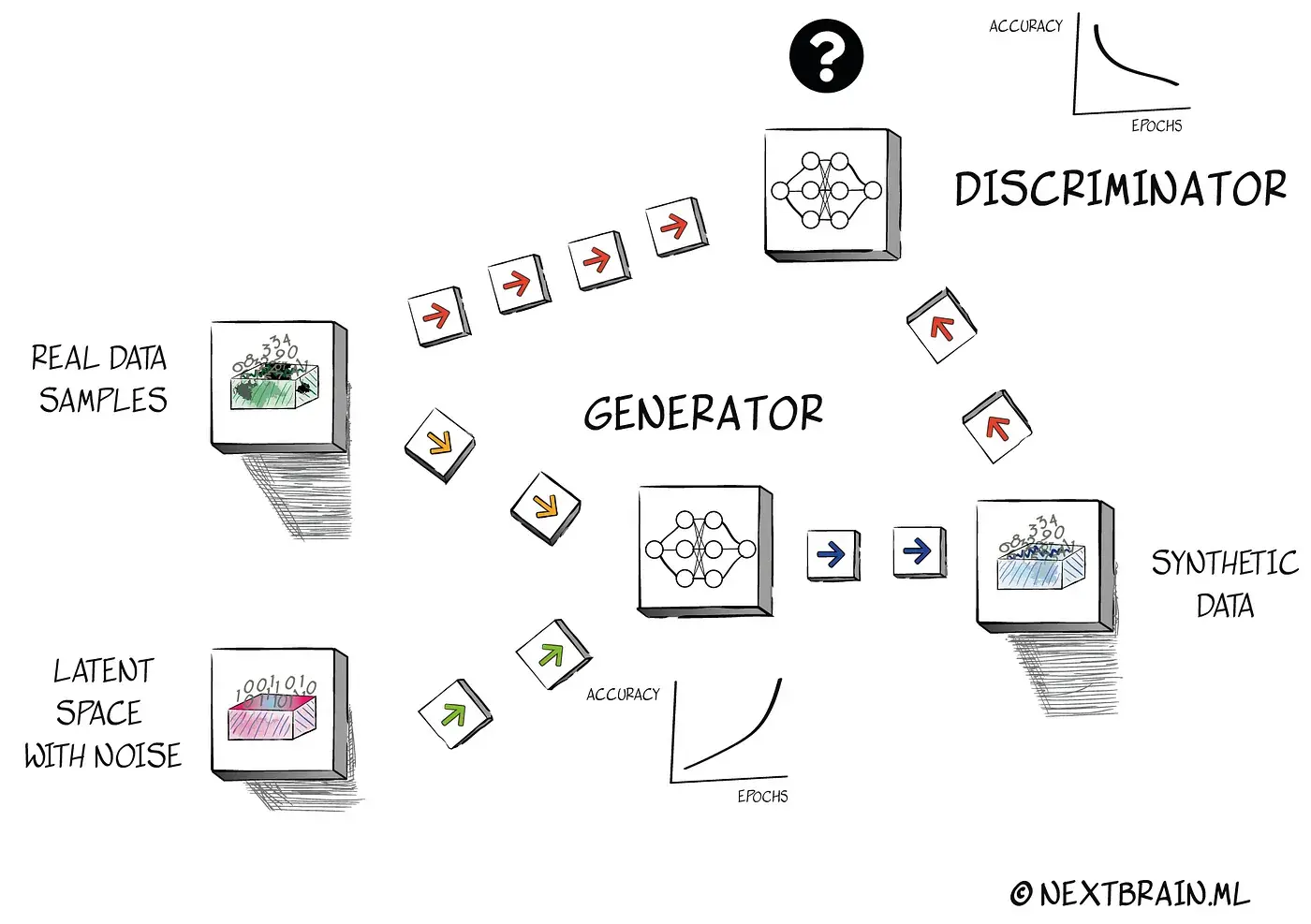
Addressing the Limitations of GANs The core technology behind nbsynthetic is the Generative Adversarial Network (GAN). GANs consist of two neural networks, the generator and the discriminator, that compete against each other. Training both models simultaneously can lead to instability and mode collapse. To address these issues, nbsynthetic adopts a non-conditional GAN approach. This configuration is quite versatile for active spreadsheet users who may want to make predictions on different features.
Building a Simple and Robust GAN with nbsynthetic To ensure a simple and robust unsupervised GAN, nbsynthetic incorporates the following considerations:
You can find the library in Githubhere.
You can also find a most comprehensible description of the libraryhere.
- Initialization: Random weight initialization and Batch Normalization are used to break the symmetry and stabilize learning.
- Convergence: Instead of using convolutional nets, nbsynthetic adopts a simple and dense architecture suitable for small sample size tabular data.
- Activation Functions: LeakyReLU is employed for both the generator and discriminator sequential models. A tanh activation function is used for the generator, while the discriminator uses a sigmoid function.
- Optimization: Stochastic gradient descent with the Adam optimizer is employed, with a small learning rate and reduced momentum term to enhance stability.
- Noise Injection: Noise injection using a fixed-length random vector