
At the heart of machine learning lies a fundamental concept: algorithms. These sets of instructions guide computers to perform tasks, from simple calculations to complex problem-solving operations. Understanding these algorithms can be daunting, but fear not. This article demystifies some of the most common machine learning algorithms, breaking down their essence and applications.
The Building Blocks: Understanding Algorithms
An algorithm is essentially a recipe for solving a problem. It comprises a finite series of steps, executed in a specific sequence, to accomplish a particular task. However, it’s crucial to note that an algorithm is not a complete program or code; it is the logic underlying a solution to a problem.
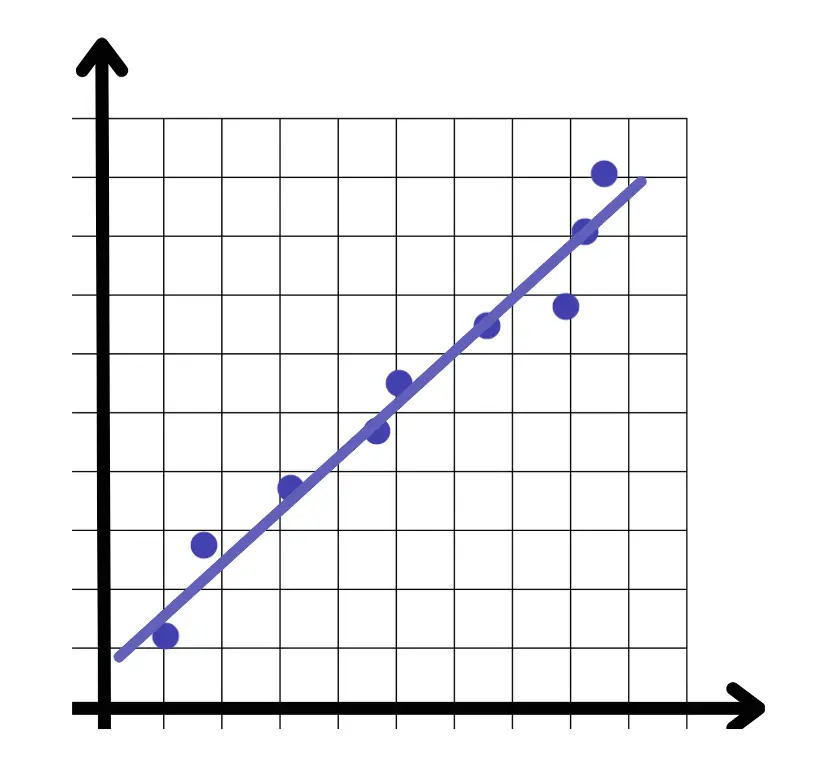
A linear regression model tries to fit a regression line to the data points that best represents the relations or correlations.
Linear Regression
Linear regression is a supervised learning algorithm that serves as a foundational block in machine learning. It seeks to model the relationship between a continuous target variable and one or more predictors. By fitting a linear equation to observed data, linear regression helps predict outcomes based on new inputs. Imagine trying to predict house prices based on their size and location; linear regression enables this by identifying the linear relationship between these variables.
Support Vector Machines (SVM)
SVM is another supervised learning algorithm, primarily used for classification tasks. It distinguishes between categories by finding the optimal boundary—the decision boundary—that separates different classes with as wide a gap as possible. This capability makes SVM particularly useful in situations where the distinction between classes is not immediately obvious.
Bayes’ theorem
Naive Bayes
The Naive Bayes classifier operates on a simple assumption: the features it analyzes are independent of each other. Despite this simplicity, Naive Bayes can be incredibly effective, particularly in text classification tasks like spam detection. It applies Bayes’ theorem, updating the probability of a hypothesis as more evidence becomes available.
Logistic Regression
Logistic regression is widely used for binary classification problems—situations where there are only two possible outcomes. By applying the logistic (or sigmoid) function, it transforms linear relationships into probabilities, offering a powerful tool for binary decisions. Whether predicting customer churn or identifying spam emails, logistic regression provides clarity in a binary world.
K-Nearest Neighbors (KNN)
KNN is a versatile algorithm used for both classification and regression. It predicts the value or class of a data point based on the majority vote or average from its ‘K’ nearest neighbors. The beauty of KNN lies in its simplicity and effectiveness, particularly in applications where the relationship between data points is a significant predictor of their classification.
If K is set to five the classes of five closest points are checked, prediction is done according to the majority class.
Decision Trees
Decision trees split data into branches to represent a series of decision paths. They are intuitive and easy to interpret, making them popular for tasks requiring clarity on how decisions are made. While decision trees are powerful, they are prone to overfitting, especially with complex data.
Example of a Decision Tree
Random Forests
Random Forests improve upon decision trees by creating an ensemble of trees and aggregating their predictions. This approach reduces the risk of overfitting, leading to more accurate and robust models. Random Forests are versatile, applicable to both classification and regression tasks.
Gradient Boosted Decision Trees (GBDT)
GBDT is an ensemble technique that boosts the performance of decision trees. By sequentially correcting errors of previous trees, GBDT combines weak learners into a strong predictive model. This method is highly effective, offering precision in both classification and regression tasks.
K-means Clustering
K-means clustering groups data points based on similarity, a fundamental technique in unsupervised learning. By partitioning data into K distinct clusters, K-means helps identify inherent groupings within the data, useful in market segmentation, anomaly detection, and more.
Principal Component Analysis (PCA)
PCA is a dimensionality reduction technique that transforms a large set of variables into a smaller one that still contains most of the information in the large set. By identifying the principal components, PCA simplifies complexity, enabling clearer insights and more efficient computation.
Wrapping Up
Machine learning algorithms are the engines driving advances in AI and data science. From predicting outcomes with linear regression to grouping data with K-means clustering, these algorithms offer a toolkit for solving a wide array of problems. Understanding the core principles behind these algorithms not only demystifies machine learning but also opens up a world of possibilities for innovation and discovery. Whether you’re a seasoned data scientist or a curious enthusiast, the journey into the world of machine learning algorithms is both fascinating and immensely rewarding.
To simplify your work with AI, we’ve developedNext Brain AI, equipped with pre-built algorithms to effortlessly extract insights from your data.Schedule a demo todayto witness how it can empower you in making strategic decisions.
- Etiquetasalgorithms,classification accuracy,cluster analysis,DBSCAN,decision trees,dimensionality reduction,ensemble learning,GBDT,K-means clustering,K-nearest neighbors,linear regression,logistic regression,Machine Learning,naive Bayes,PCA,Predictive Analytics,random forests,support vector machines,unsupervised learning