Model intelligence
01
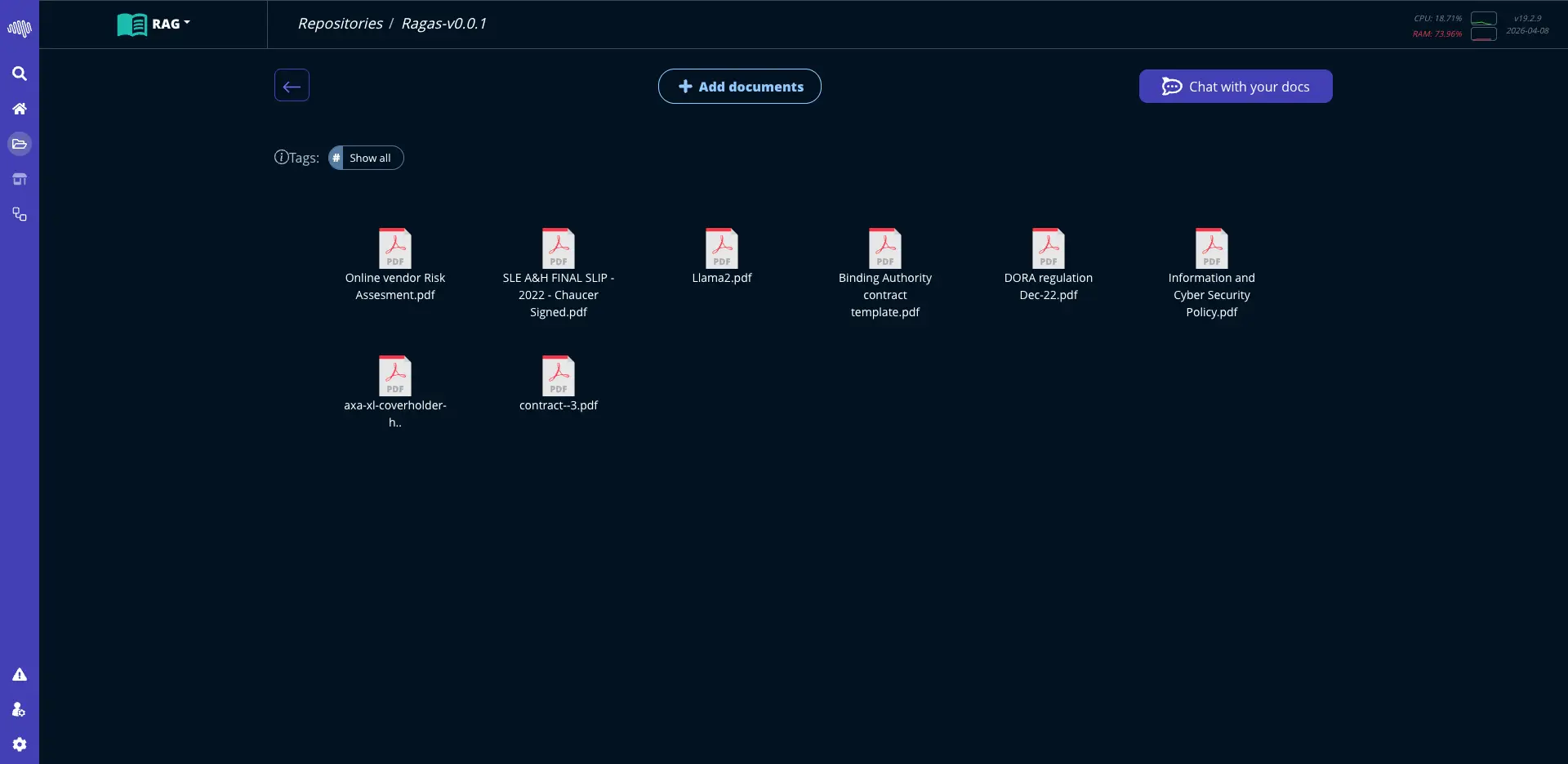
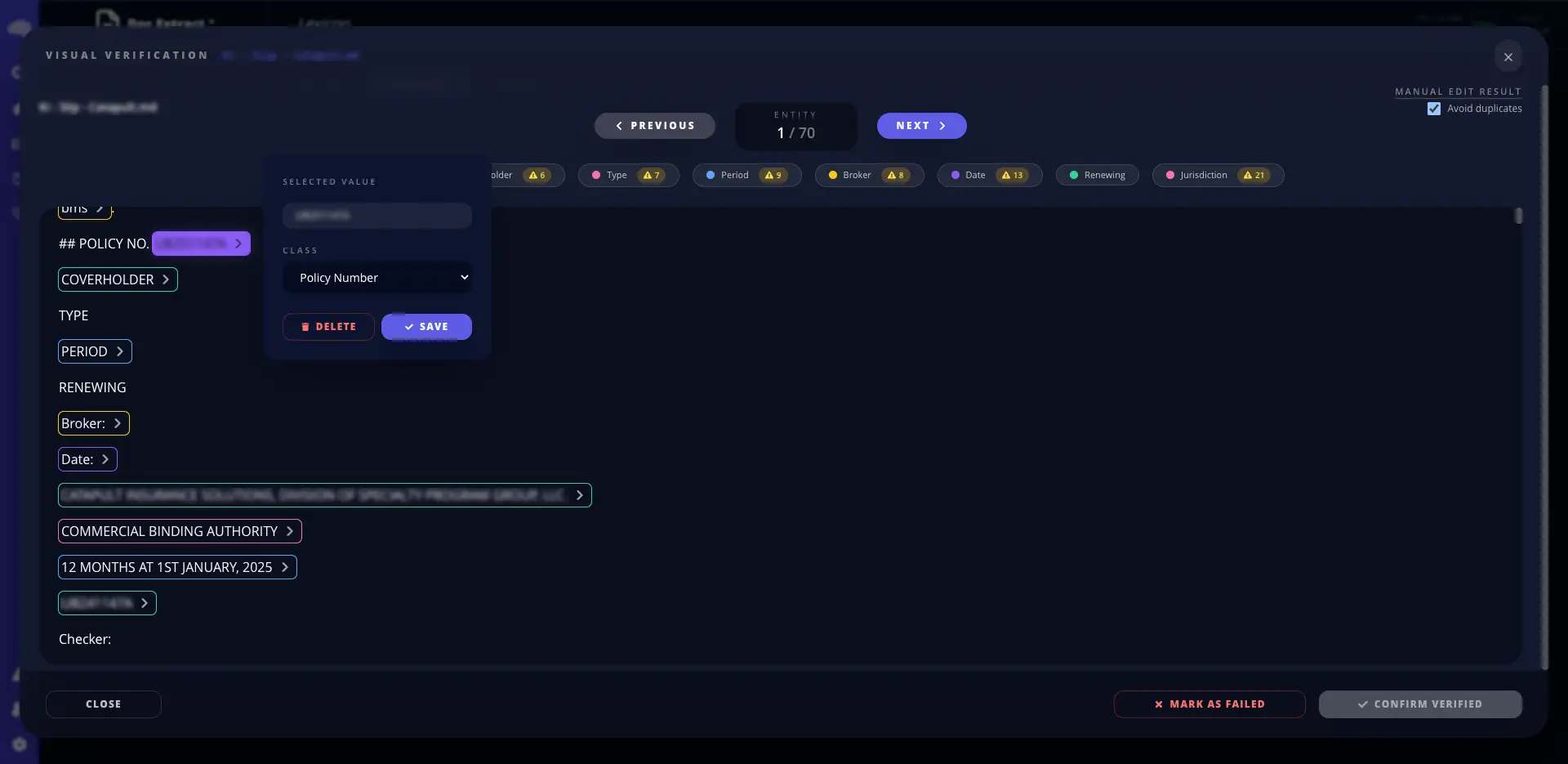
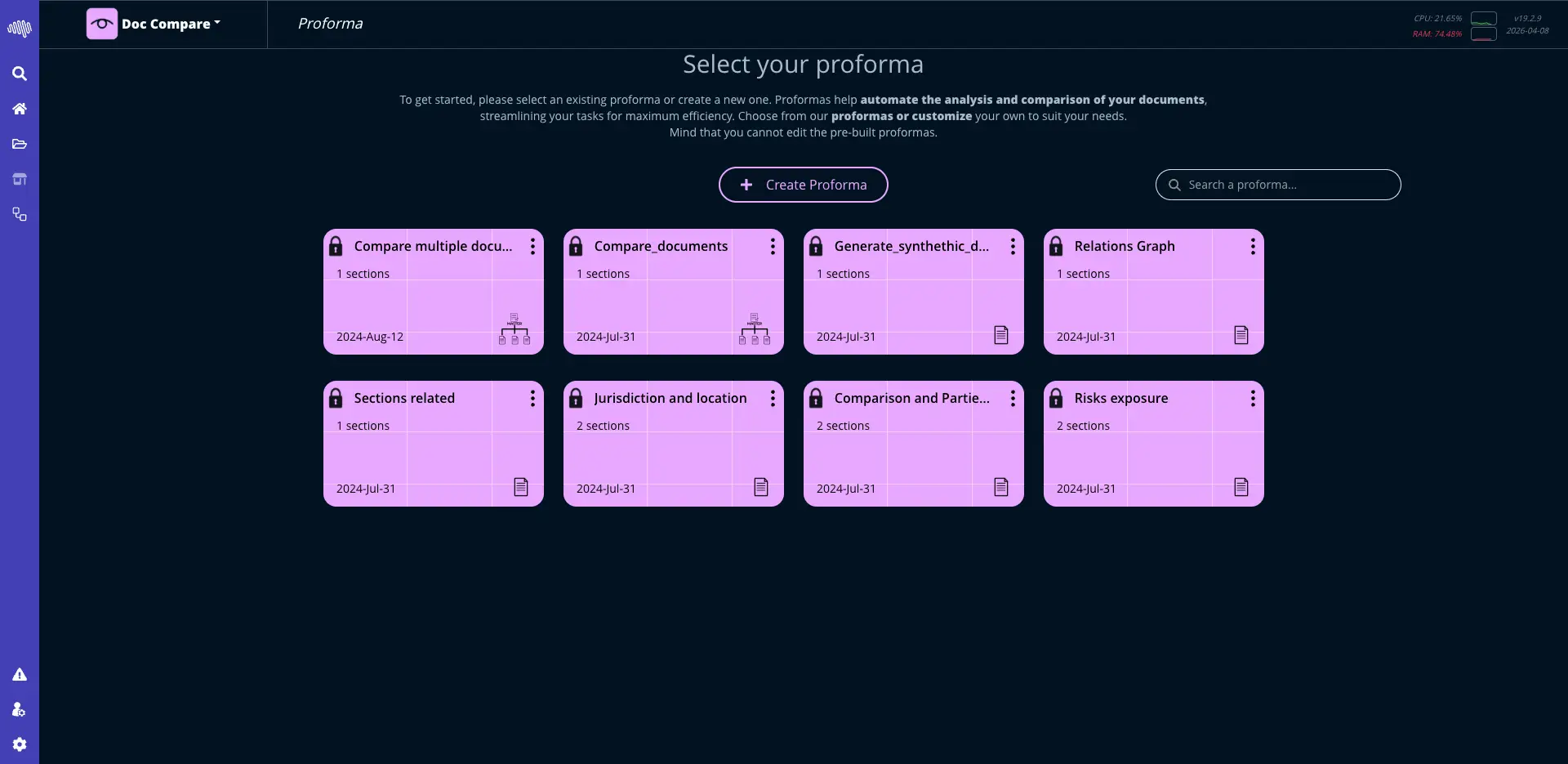
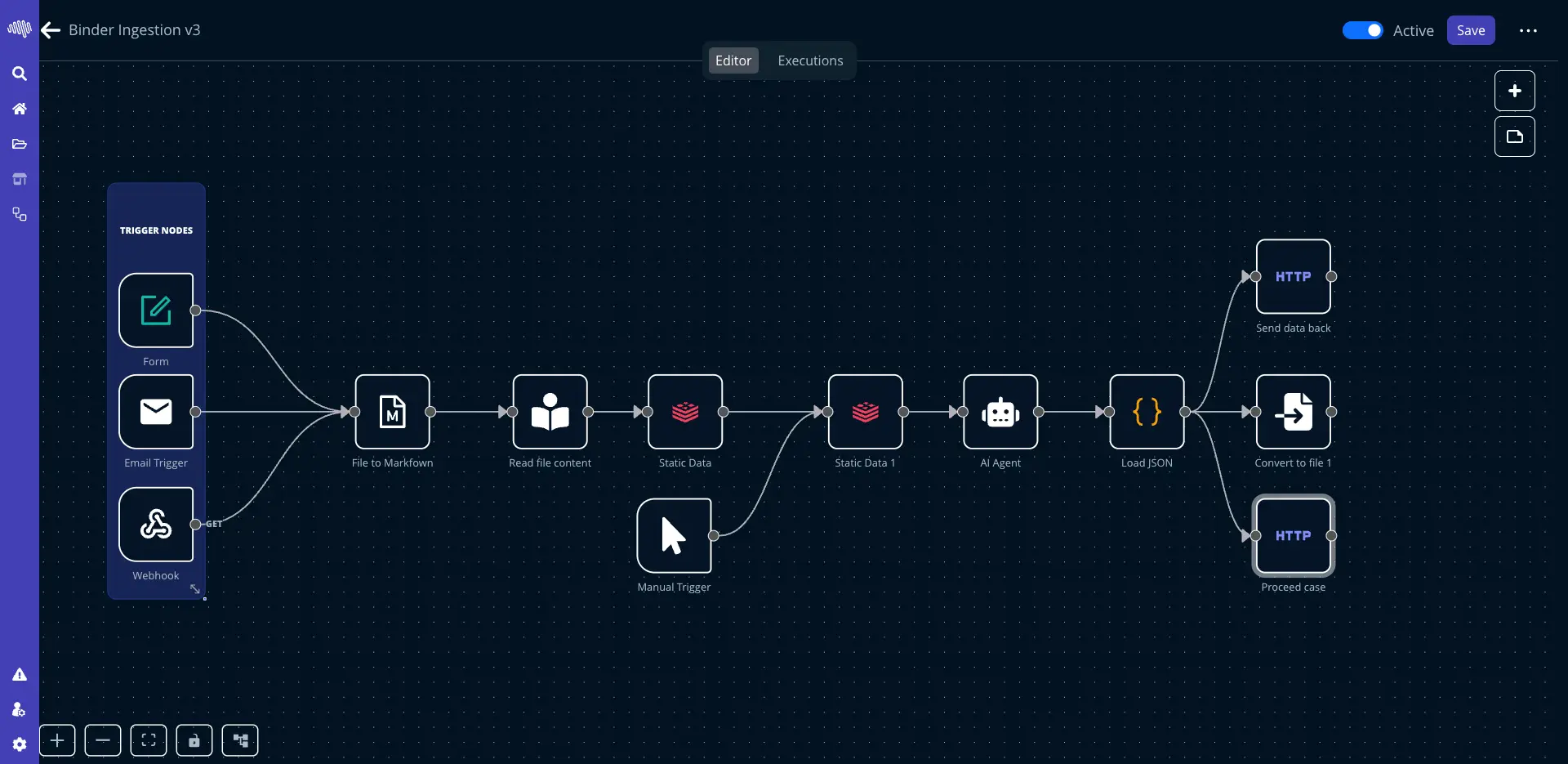
AutoML: Machine Learning
Leverage advanced AI models to extract insights, make predictions, and automate decision-making processes.
Faster model cycles
10x
quicker experimentation
Forecasting and anomaly detection Low-code training and deployment Business-ready predictions
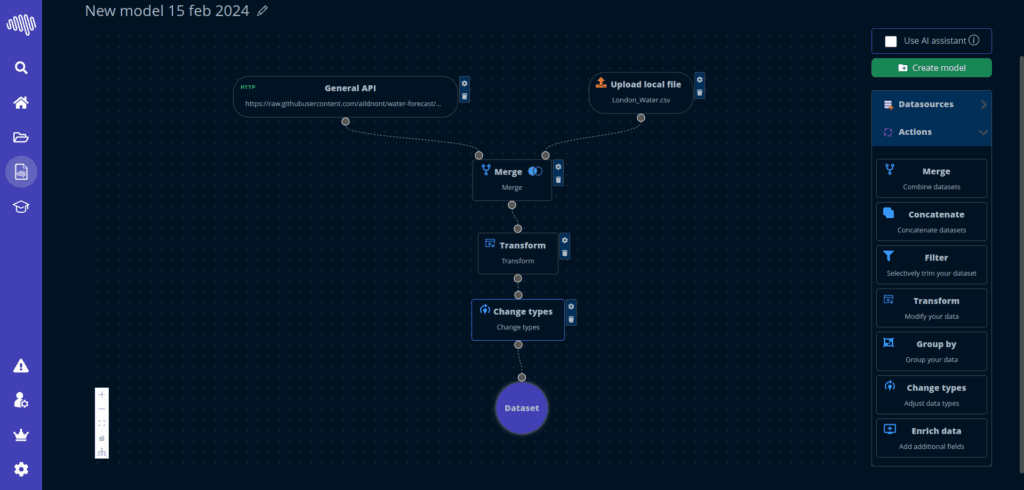
Enterprise-ready
Structured interfaces with a clean path from configuration to deployment.