Referencia de herramientas AutoML No-code
NextBrain es la plataforma AutoML No-code líder del mercado, y con razón. Hemos puesto nuestra plataforma a prueba frente a nuestros competidores, utilizando el mismo conjunto de datos y condiciones de entrenamiento predeterminadas para cada uno.
Los resultados hablan por sí solos - NextBrain consistently supera a la competencia en precisión del modelo, tiempo de formación y coste.. Nos comprometemos a proporcionar a nuestros usuarios las mejores herramientas y recursos posibles para ayudarles a alcanzar el éxito, y nuestra evaluación comparativa del rendimiento es sólo una forma de demostrar nuestra dedicación a la excelencia.
Elija NextBrain entre otras herramientas (Azure Machine Learning, Amazon SageMaker, BigML) y experimente el mejor rendimiento de AutoML No-code.

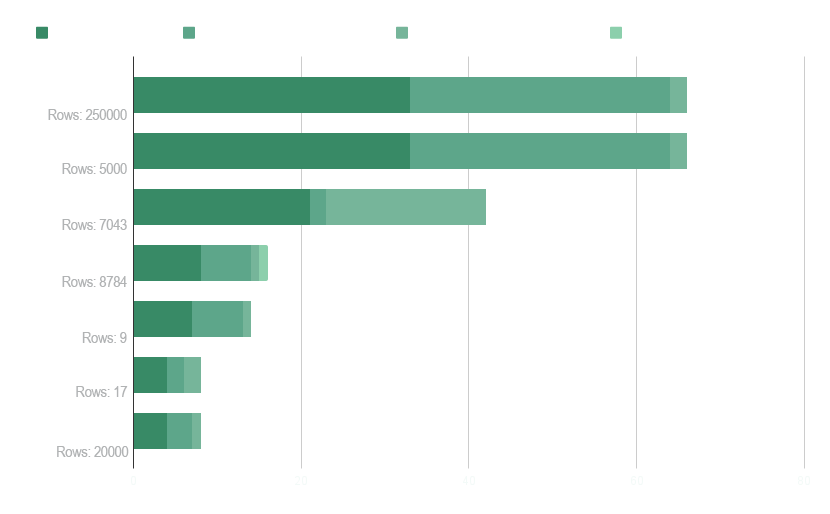
Conjunto de datos
En nuestras evaluaciones de rendimiento, hemos elegido conjuntos de datos con distinto número de filas y columnas para problemas de clasificación binaria, clasificación multiclase y regresión multivariante.
También utilizamos conjuntos de datos especiales con pocas filas y entrenamos los modelos con datos sintéticos generados con NextBrain a partir de muestras de datos originales.
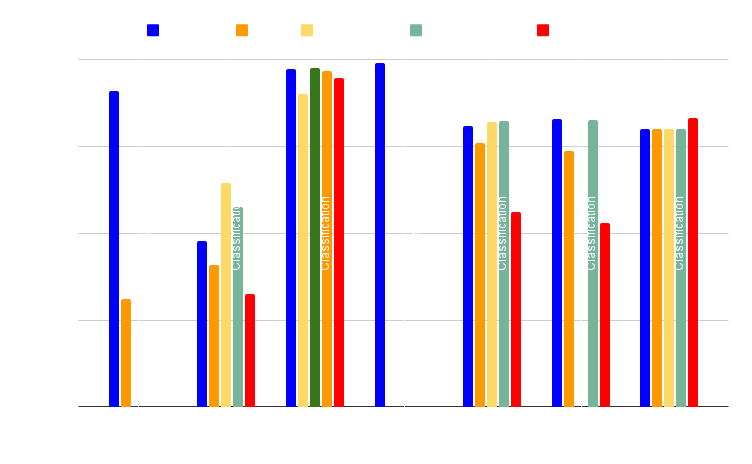
Precisión Benchmark
En nuestras evaluaciones de rendimiento, hemos elegido conjuntos de datos con distinto número de filas y columnas para problemas de clasificación binaria, clasificación multiclase y regresión multivariante.
También utilizamos conjuntos de datos especiales con pocas filas y entrenamos los modelos con datos sintéticos generados con NextBrain a partir de muestras de datos originales.
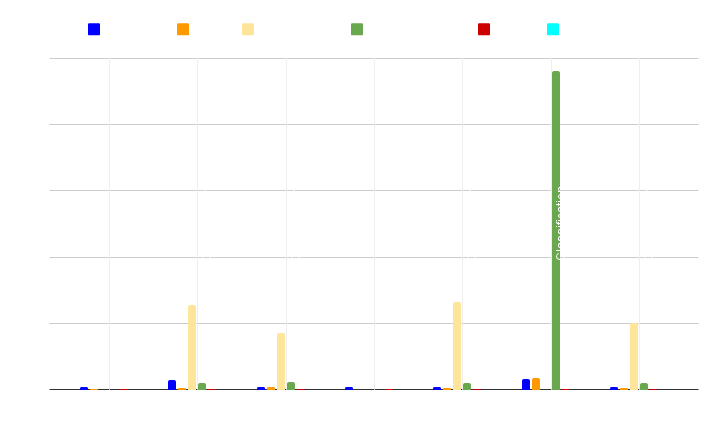
Tiempo de formación
En nuestras evaluaciones de rendimiento, hemos elegido conjuntos de datos con distinto número de filas y columnas para problemas de clasificación binaria, clasificación multiclase y regresión multivariante.
También utilizamos conjuntos de datos especiales con pocas filas y entrenamos los modelos con datos sintéticos generados con NextBrain a partir de muestras de datos originales.
Comparación de características

- Herramienta integral: El proveedor de la herramienta se encarga de todas las necesidades de software y hardware, incluidas la instalación, la integración y la configuración.
- Aplicación web: No es necesario descargar ni instalar esta herramienta porque está disponible como aplicación web.
- Plugin Spreadsheet: La aplicación está disponible como Google Sheets Ad-on disponible en GS market place.
- Despliegue en servidor de usuario: La aplicación web puede copiarse en un servidor definido por el usuario para cumplir los requisitos de seguridad.
- Servicios API / SDKLos servicios de API permiten a los usuarios acceder a la funcionalidad y los datos de la herramienta. Los usuarios se benefician de su flexibilidad, integración, innovación y colaboración.
- Conector de Base de Datos: Un conector de base de datos SQL permite la integración y manipulación de una base de datos SQL desde otros sistemas y aplicaciones, y proporciona ventajas de rendimiento, escalabilidad, seguridad y facilidad de uso.
- API de Marketing (Dataslayer.ai)Conector a Dataslayer.ai donde hay más de 40 conectores disponibles para datos de marketing.
- Preparación automática de datos: La aplicación realiza la preparación básica y avanzada de los datos y la ingeniería de características antes de entrenar un modelo para obtener información más fiable.
- Generación de datos sintéticos: Generación de datos sintéticos para obtener conjuntos de datos de muestra más amplios y mejorar la calidad de los modelos. También es útil para la anonimización de datos.
- Modelos personalizables: Opciones como el algoritmo a utilizar y su ajuste fino están disponibles como opciones avanzadas.
- Dashboards interactivos: Herramienta para visualizar y compartir datos y modelos de aprendizaje automático.
Dataset que utilizamos
ROI - Descargar
El retorno de la inversión (ROI) es una métrica clave que se utiliza para evaluar la eficacia de una campaña de marketing. Se calcula dividiendo el beneficio neto que genera una campaña por el coste total de la misma, y suele expresarse en porcentaje. El ROI se considera una métrica importante para las campañas de marketing porque permite medir la rentabilidad de una campaña y compararla con otras campañas o inversiones. Esto puede ayudar a los responsables de marketing a determinar qué campañas son las más eficaces y dónde asignar sus recursos en el futuro. Además, el ROI es importante porque ayuda a alinear los esfuerzos de marketing con los objetivos empresariales. Al centrarse en campañas que generan un alto ROI, los profesionales del marketing pueden garantizar que sus esfuerzos contribuyen al éxito financiero general de la empresa. Esto es especialmente importante en el entorno empresarial actual, en el que las empresas están sometidas a una presión cada vez mayor para demostrar el valor de su gasto en marketing.
![]() Objetivo MRR (Ingresos Recurrentes Mensuales)
Objetivo MRR (Ingresos Recurrentes Mensuales)
 Fuente de DatosDataslayer.ai
Fuente de DatosDataslayer.ai
 Licencia: Archivos de datos © Dataslayer.ai
Licencia: Archivos de datos © Dataslayer.ai
LiDAR forestal Descargar
La tecnología de detección y medición de distancias por luz (LIDAR) se ha convertido en una herramienta esencial para la conservación del medio ambiente. Lidar es una tecnología que utiliza un láser para apuntar a un objeto o una superficie y cronometrar el retorno de la luz reflejada al receptor. Puede utilizarse, por ejemplo, para generar representaciones tridimensionales informatizadas de zonas de la superficie terrestre. Por ello, ecologistas y biólogos han encontrado en esta tecnología el mejor aliado para sus actividades de detección, clasificación y conservación. Sin embargo, esta tecnología requiere importantes recursos informáticos para procesar los millones de puntos obtenidos para un solo metro cuadrado de análisis. Todos estos puntos deben clasificarse y segmentarse, y existen varias metodologías matemáticas y computacionales que pueden utilizarse para procesar todos estos datos y producir resultados legibles e interpretables. Este conjunto de datos contiene una representación LIDAR de tres árboles. Cada punto está representado por sus coordenadas X, Y y Z. Así pues, el conjunto de datos sólo tiene tres variables de entrada (x,y,z) y un objetivo (Árbol).
![]() Objetivo Árbol
Objetivo Árbol
Fuente de datos: CIFOR y la Universidad de Wageningen
Licencia: Archivos de datos © CIFOR y Universidad de Wageningen
Referencia:
González de Tanago, J, Lau, A, Bartholomeus, H, et al. (2018). Estimación de la biomasa sobre el suelo de grandes árboles tropicales con LiDAR terrestre. Methods Ecol Evol. 9: 223- 234. https://doi.org/10.1111/2041-210X.12904
Bosón de Higgs - Descargar
Este conjunto de datos contiene una tarea de referencia para algoritmos de clasificación de aprendizaje automático diseñada para distinguir entre un proceso de señal en el que se producen nuevos bosones de Higgs teóricos y un proceso de fondo con productos de desintegración idénticos pero características cinemáticas distintas (Baldi P. et al, 2014). El conjunto de datos contiene las siguientes columnas: la columna objetivo ("Label") es la etiqueta de clase (1 para señal, 0 para fondo). Hay 28 características (21 de bajo nivel y 7 de alto nivel): lepton pT, lepton eta, lepton phi, missing energy magnitude, missing energy phi, jet 1 pt, jet 1 eta, jet 1 phi, jet 1 b-tag, jet 2 pt, jet 2 eta, jet 2 phi, jet 2 b-tag, jet 3 pt, jet 3 eta, jet 3 phi, jet 3 b-tag, jet 4 pt, jet 4 eta, jet 4 phi, jet 4 b-tag, m_jj, m_jjj, m_lv, m_jlv, m_bb, m_wbb, m_wwbb. La descripción detallada de estas columnas puede consultarse en Baldi P. et al. 2014.
![]() ObjetivoEtiqueta
ObjetivoEtiqueta
Fuente de datos: https://archive.ics.uci.edu/ml/datasets/higgs
Licencia: Archivos de datos © Daniel Whiteson
Referencia:
Baldi, P., Sadowski, P. y Whiteson, D. (2014). Búsqueda de partículas exóticas en física de altas energías con aprendizaje profundo. Comunicaciones de la naturaleza, 5(1), 1-9.
Leyes universales de la física - Descargar
Los algoritmos de aprendizaje automático se utilizan actualmente para automatizar el descubrimiento de principios físicos y ecuaciones rectoras basándose en datos y no en la resolución de complejos sistemas de ecuaciones. Al abordar el problema clásico de modelar objetos que caen de diferentes tamaños y masas, podemos identificar una serie de cuestiones difíciles que deben ser gestionadas por los recientes métodos basados en datos para el descubrimiento automatizado de la física. Nuestro objetivo es abordar el problema clásico de modelar la caída de objetos de diferentes tamaños y masas para el descubrimiento automatizado de la física. La investigación teórica sobre las fuerzas de los fluidos en una esfera idealizada ha dado lugar a una extensa historia de investigación científica. Además de la gravedad y el arrastre, la trayectoria de una bola puede verse modificada por su giro a través de la fuerza Magnus o fuerza de sustentación, que actúa ortogonalmente al arrastre. Otras variables que pueden afectar a las fuerzas producidas por la caída de una pelota son la temperatura del aire, el viento, la elevación y la forma de la superficie de la pelota (de Silva et al. 2020). La fuente del conjunto de datos es el artículo "Discovery of Physics From Data: Universal Laws and Discrepancies" (de Silva et al. 2020). El conjunto de datos incluye observaciones para nueve tipos diferentes de pelotas: una pelota de golf, una pelota de béisbol, una pelota de tenis, una pelota de baloncesto azul, una pelota de baloncesto verde, una pelota de whiffle, una pelota de whiffle amarilla y una pelota de whiffle naranja.
![]() Objetivo Tiempo de aterrizaje
Objetivo Tiempo de aterrizaje
Fuente de datos: https://www.frontiersin.org/files/Articles/479363/frai-03-00025-HTML/image_m/frai-03-00025-t001.jpg
Licencia: Datos © Silva, B. M., Higdon, D. M., Brunton, S. L., Kutz, J. N
Referencia:
de Silva, B. M., Higdon, D. M., Brunton, S. L., & Kutz, J. N. (2020). Discovery of Physics From Data: Leyes Universales y Discrepancias. Frontiers in artificial intelligence, 3, 25. https://doi.org/10.3389/frai.2020.00025
Deserción de Telcos Descargar
La pérdida de clientes, también conocida como desgaste de clientes, se refiere al porcentaje de clientes que dejan de utilizar los productos o servicios de una empresa en un periodo de tiempo determinado. Es un indicador importante para una empresa de telecomunicaciones porque la pérdida de clientes puede tener implicaciones financieras significativas. Las empresas de telecomunicaciones suelen tener costes fijos elevados, como el coste de construir y mantener redes e infraestructuras, y estos costes deben repartirse entre una amplia base de clientes para ser viables desde el punto de vista financiero. Si la tasa de rotación de clientes es alta, puede provocar un descenso en el número total de clientes, lo que puede dificultar que la empresa cubra sus costes fijos. En última instancia, esto puede conducir a una disminución de la rentabilidad. Mediante el seguimiento de la tasa de rotación de clientes, una empresa de telecomunicaciones puede identificar tendencias y patrones en el comportamiento de los clientes y tomar medidas para mejorar la retención y reducir la tasa de rotación. Esto podría incluir ofrecer precios más competitivos, mejorar el servicio al cliente o introducir nuevos productos y servicios más atractivos para los clientes.
![]() Objetivo Deserción
Objetivo Deserción
Fuente de datos: Conjunto de datos adaptado de IBM Business Analytics Community (https://community.ibm.com/community/user/businessanalytics/blogs/steven-macko/2019/07/11/telco-customer-churn-1113).
Licencia: Archivos de datos © IBM
Datos del Tiempo Descargar
Predecir el tiempo es importante para las comunidades por varias razones. En primer lugar, unas previsiones meteorológicas precisas pueden ayudar a la población a mantenerse a salvo al permitirle prepararse para fenómenos meteorológicos extremos, como huracanes, inundaciones y tormentas de nieve. Por ejemplo, si una comunidad sabe que se avecina una gran tormenta, puede tomar medidas para asegurar sus hogares, evacuar si es necesario y abastecerse de provisiones. Además de por motivos de seguridad, las previsiones meteorológicas precisas también son importantes por razones económicas. Muchas empresas e industrias se ven afectadas por el tiempo, y dependen de previsiones precisas para planificar sus operaciones y tomar decisiones informadas. Por ejemplo, los agricultores necesitan saber qué tiempo hará para decidir cuándo plantar y cosechar sus cultivos, y las empresas de construcción necesitan saber si hará frío o calor para planificar sus horarios de trabajo. Por último, las previsiones meteorológicas precisas son importantes para la vida cotidiana. Permiten a la gente planificar sus actividades al aire libre y tomar decisiones sobre qué ropa ponerse y cómo viajar. También pueden influir en el estado de ánimo y el bienestar de las personas, ya que el mal tiempo puede hacer que la gente se sienta decaída o incluso afectar a su salud mental.
![]() Objetivo Tiempo
Objetivo Tiempo
Fuente de datos: Adaptado de los datos meteorológicos horarios históricos de 2012-2017 (https://www.kaggle.com/datasets/selfishgene/historical-hourly-weather-data?select=pressure.csv).
Licencia: Este conjunto de datos está disponible bajo la licencia Open Database License: http://opendatacommons.org/licenses/odbl/1.0/. Cualquier derecho sobre los contenidos individuales de la base de datos se licencia bajo la Licencia de Contenidos de Bases de Datos: http://opendatacommons.org/licenses/dbcl/1.0/

 +34 910 054 348
+34 910 054 348 +44 (0) 7903 493 317
+44 (0) 7903 493 317