
El marketing digital y la estrategia de marca presentan desafíos significativos para los comercializadores y estrategas en medio de tendencias y comportamientos del consumidor en evolución. El éxito depende de alcanzar a la audiencia adecuada con contenido relevante y optimización de costos. Sin embargo, no todas las marcas tienen acceso extenso a datos que informen sus decisiones. Aquí es donde la generación de datos sintéticos juega un papel crucial, augmentando muestras limitadas y extrayendo información valiosa.
El papel de los datos en el marketing digital
Los datos empoderan el marketing digital, permitiendo a las marcas tomar decisiones basadas en datos y optimizar estrategias. Sin embargo, la recopilación de datos detallados en contextos de rápido cambio plantea desafíos. Debido a que los especialistas en marketing a menudo trabajan con conjuntos de datos pequeños o medianos que carecen de significancia estadística, lo que dificulta la previsión precisa del éxito de las campañas y la determinación del punto de saturación del gasto publicitario.
Datos Sintéticos Tabulares: Desbloqueando su Potencial
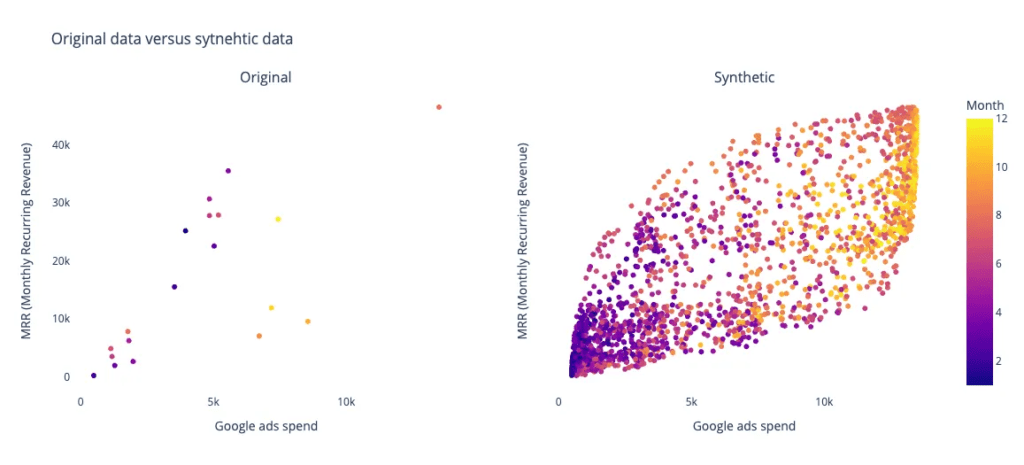
Mientras la generación de datos sintéticos gana atención en los campos de imágenes y texto, su aplicación a datos tabulares a menudo se pasa por alto. Los datos sintéticos tabulares, estructurados en filas y columnas, tienen un enorme potencial para los comercializadores digitales y estrategas. Aprovechando las redes generativas antagónicas (GAN), una tecnología de aprendizaje automático de vanguardia, los datos sintéticos amplían los conjuntos de datos y mejoran la "resolución", revelando información adicional.
Redes Generativas Antagónicas (GANs): Potenciando la Generación de Datos Sintéticos
Los GANs son una poderosa innovación en el aprendizaje automático que involucra dos redes neuronales, un generador y un discriminador, que compiten entre sí. El generador crea nuevas muestras de datos estadísticamente similares a los datos de entrada, mientras que el discriminador distingue entre muestras reales y sintéticas. Este juego adversarial impulsa el entrenamiento, generando datos sintéticos de alta calidad que se asemejan al conjunto de datos original.
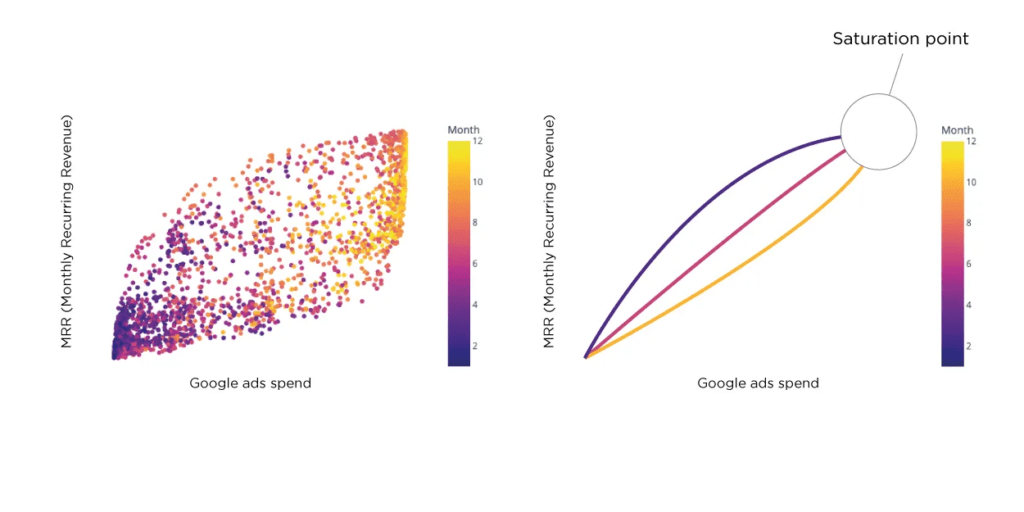
Comprendiendo el Punto de Saturación en Marketing Digital
El punto de saturación es fundamental en el marketing digital, ya que previene los rendimientos decrecientes por un gasto excesivo en publicidad. La curva S de la publicidad ilustra la relación entre el gasto y su impacto en las ventas, los ingresos o la cuota de mercado. Más allá de un cierto punto, aumentar el gasto no produce rendimientos proporcionales. Estimar el punto de saturación con precisión es un desafío, especialmente con datos limitados. Los datos sintéticos abordan esto al proporcionar un conjunto de datos más grande para el análisis y permitir predicciones más precisas.
Un Caso de Uso Práctico: Aprovechando Datos Sintéticos
Consideremos una nueva marca lanzada hace dos años, que ha llevado a cabo diversas campañas publicitarias en varias plataformas con datos limitados. Determinar si han alcanzado el punto de saturación y planificar los próximos pasos estratégicos son vitales. Generar un conjunto de datos sintético a partir de los datos originales amplía el tamaño de la muestra y ofrece información sobre el punto de saturación y otros indicadores clave.
Usando la biblioteca de Python de código abierto nbsynthetic por el equipo de NextBrain.ai, se genera datos sintéticos a partir del conjunto de datos original. Se crea un conjunto de datos sintéticos de 2000 muestras y se realiza una comparación visual entre los datos originales y sintéticos. Además, se entrena un modelo de aprendizaje automático, como un Regresor de Bosque Aleatorio, en ambos conjuntos de datos para predecir métricas clave como los Ingresos Recurridos Mensuales (MRR). Los resultados (figuras a continuación) muestran que el modelo entrenado con datos sintéticos logra una mayor estabilidad y una mejor precisión de predicción en comparación con el modelo entrenado con los datos originales de bajo tamaño de muestra.
╔═══════════════╗
RESULTADOS
╚═══════════════╝
Datos originales
-------------
Puntuación sin validación cruzada = 0.32
Puntuaciones con validación cruzada = [ 0.19254948 -7.0973158 0.1455913 0.18710539 -0.14113018]
Datos sintéticos
----------------
Puntuación sin validación cruzada = 0.80
Puntuaciones con validación cruzada = [0.8009446 0.81271862 0.79139598 0.81252436 0.83137774]
Algoritmo entrenado con datos sintéticos y probado con datos originales
-------------------------------------------------------------------
Puntuación con validación cruzada predicción = 0.71
Esta publicación se publicó originalmente en Towards Data Science. Puedes encontrar la original. aquí.

 +34 910 054 348
+34 910 054 348 +44 (0) 7903 493 317
+44 (0) 7903 493 317