
モデルインテリジェンス
01
AutoML: 機械学習
高度なAIモデルを活用して洞察を抽出し、予測を行い、意思決定プロセスを自動化します。
より速いモデルサイクル
10x
より素早い実験
予測と異常検知 ローコードでの学習とデプロイ 業務で使える予測
エンタープライズ対応
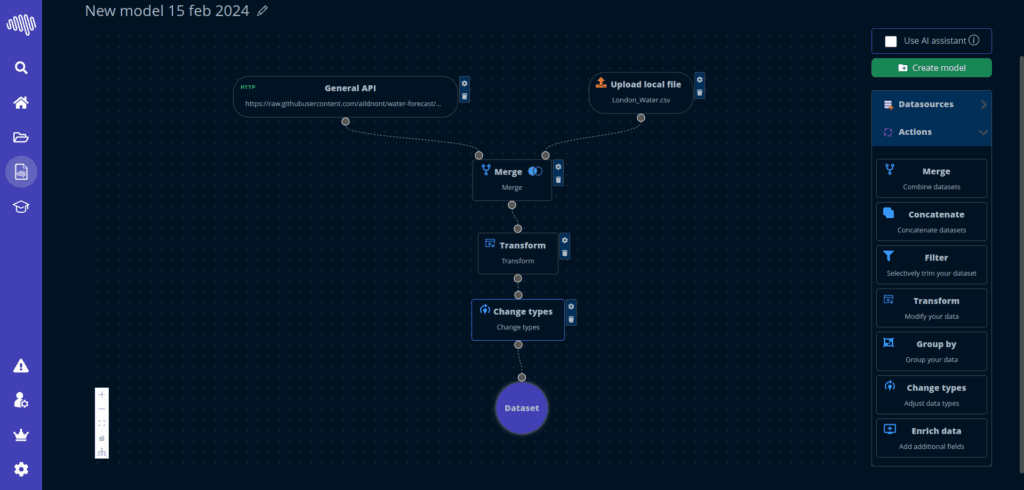
設定からデプロイまで、明快な流れを持つ構造化インターフェースです。
プラットフォームモジュール
各レイヤーは探索から本番運用へ素早く進めるよう設計されており、インターフェースは理解しやすく、測定しやすく、企業ワークフローに対応できます。
モデルインテリジェンス
01
高度なAIモデルを活用して洞察を抽出し、予測を行い、意思決定プロセスを自動化します。
より速いモデルサイクル
10x
より素早い実験
エンタープライズ対応
設定からデプロイまで、明快な流れを持つ構造化インターフェースです。
接続された知識
02
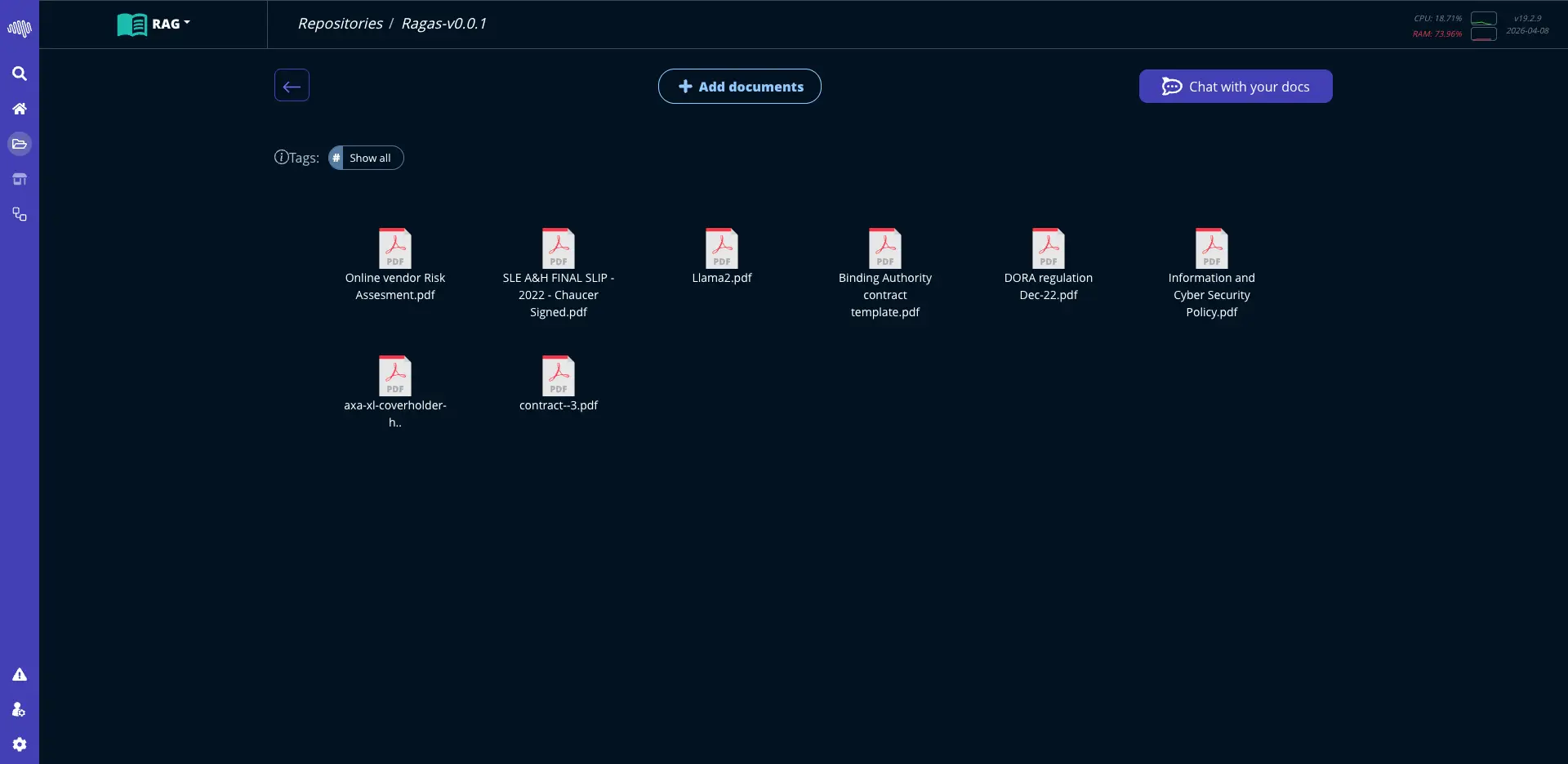
高度なRAGシステムで非構造化データを保存、整理、取得します。組織全体の情報をつなげます。
本番対応の検索取得
24/7
検索可能な組織コンテキスト
エンタープライズ対応
設定からデプロイまで、明快な流れを持つ構造化インターフェースです。
構造化ドキュメントデータ
03
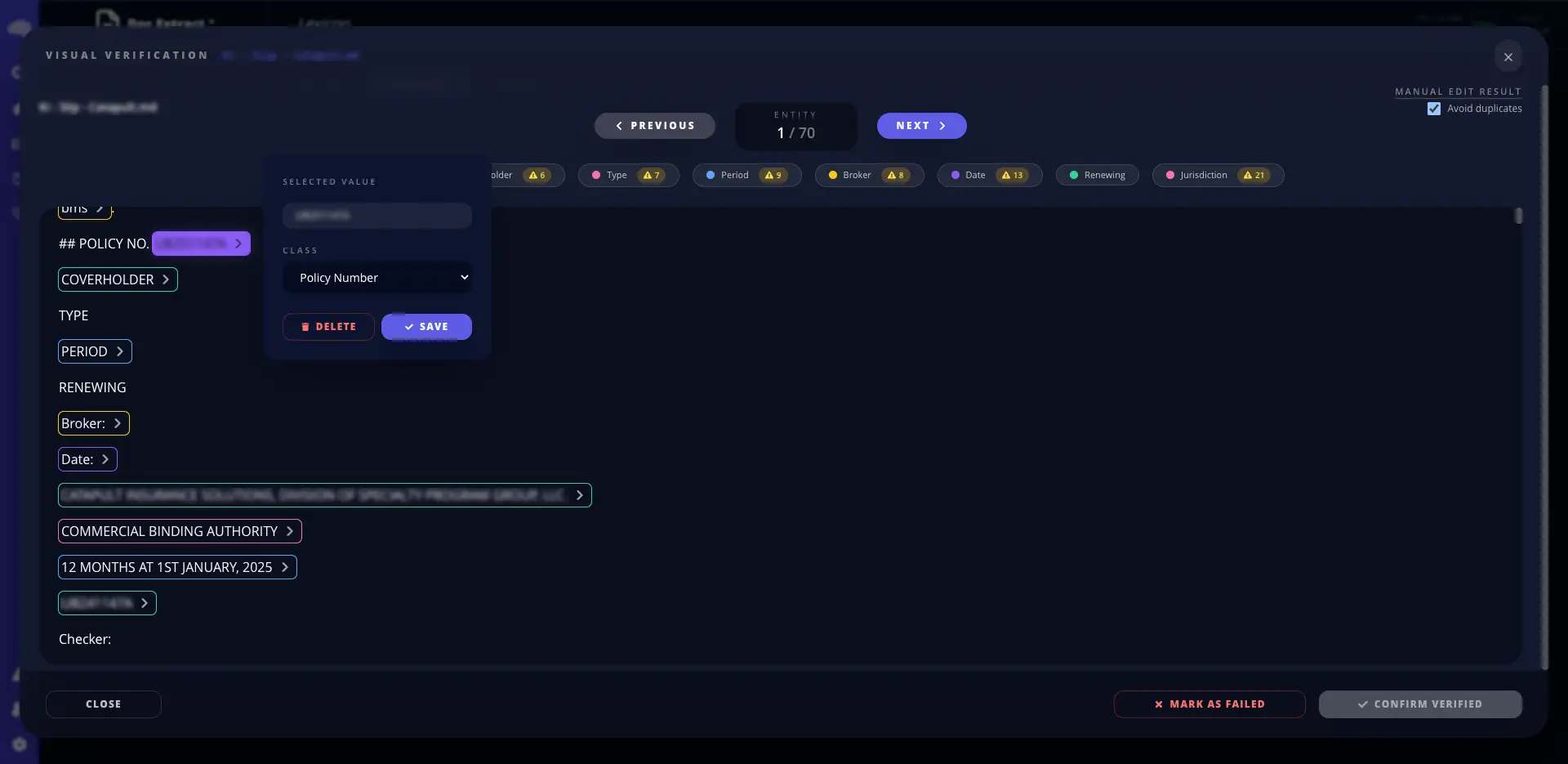
文書から構造化データを抽出し、各結果をAIで検証します。RAGと異なり、このモジュールは情報をSQLライクなデータレイヤーに書き込むため、繰り返し業務でより一貫した回答と高い拡張性を実現します。
検証済みの構造化出力
99%
下流ワークフロー向けにより整ったフィールド
エンタープライズ対応
設定からデプロイまで、明快な流れを持つ構造化インターフェースです。
ドキュメントインテリジェンス
04
文書を即座に比較し、差分、不整合、重要な変更点を詳細レポートとして生成できるAIツールです。手作業の確認負荷を減らします。
即時レビューサイクル
2x
より速い文書分析
エンタープライズ対応
設定からデプロイまで、明快な流れを持つ構造化インターフェースです。
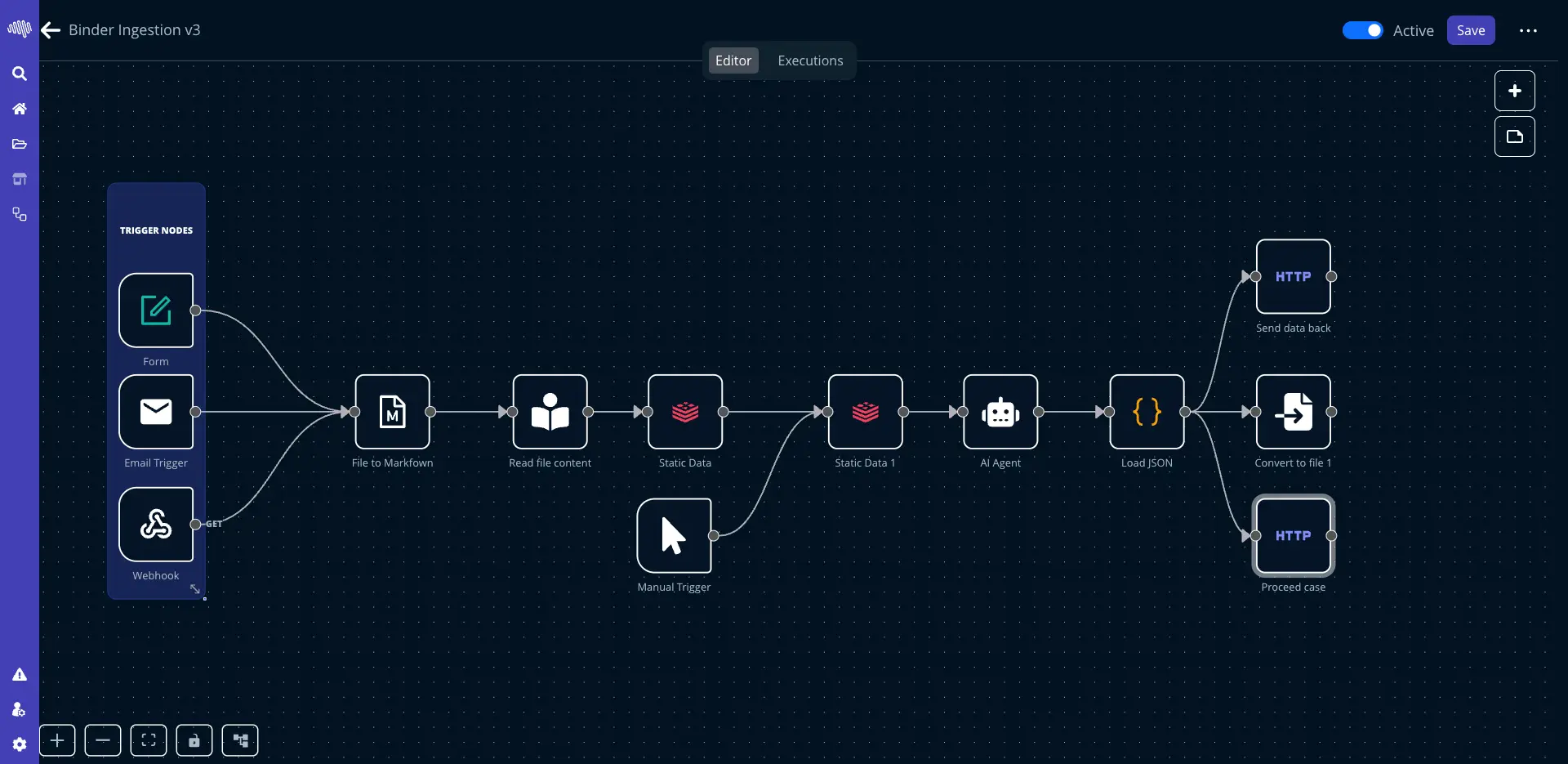
運用ワークフロー
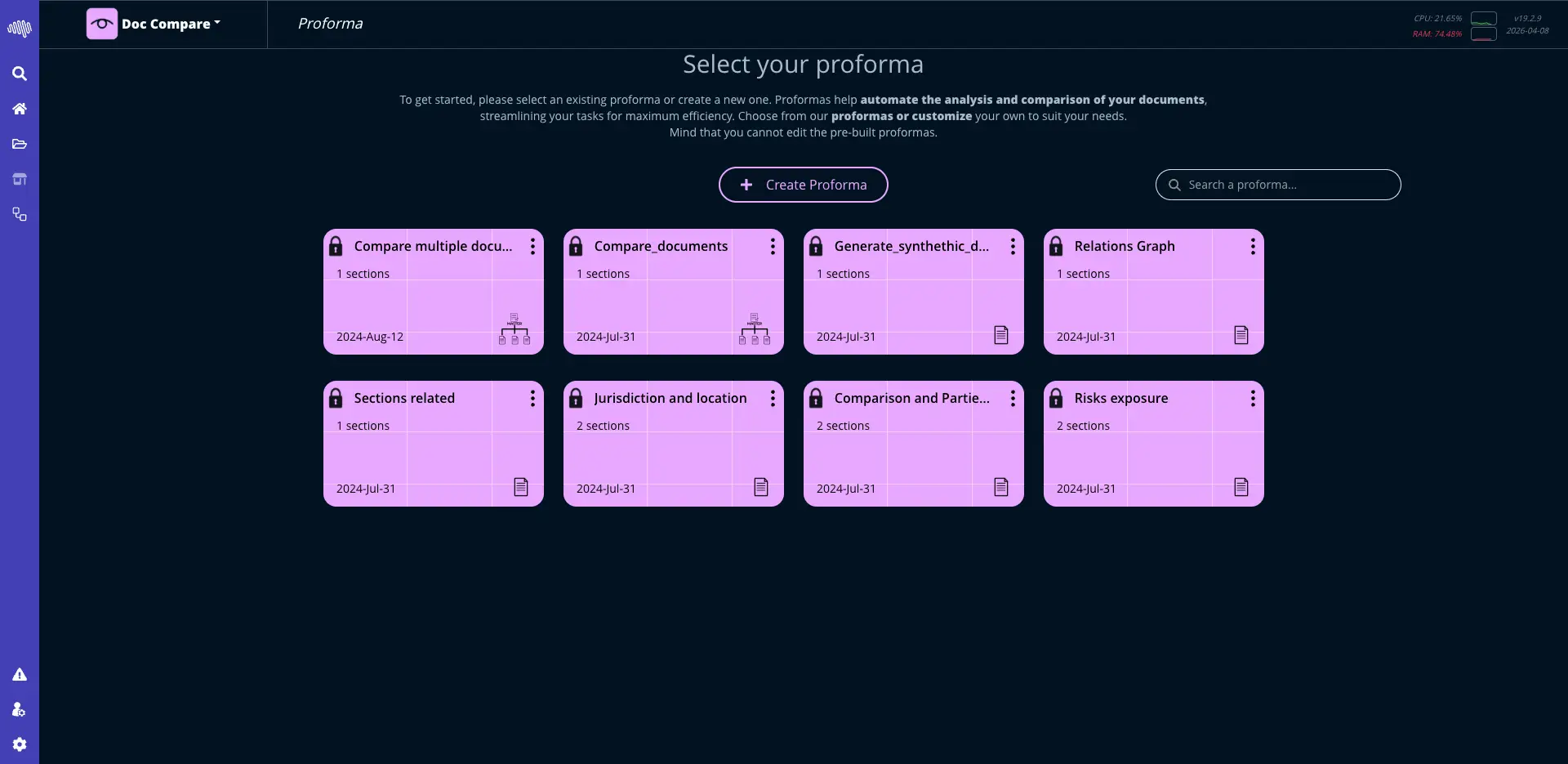
05
視覚的なインターフェースで強力な自動化ワークフローを構築します。ツールとプロセスをシームレスにつなげます。
大規模な自動化
50+
ノードと連携
エンタープライズ対応
設定からデプロイまで、明快な流れを持つ構造化インターフェースです。
導入企業
戦略立案から本番ワークフローまで、NextBrainは信頼できる自動化と測定可能な成果を必要とする組織を支援します。







企業利用を前提に設計
自動化、予測分析、安全なエンタープライズ展開を必要とするチームのための実践的なAIスタックです。
時間とともに改善する学習アルゴリズムで、複雑なワークフローを自動化します。
文書を分析し、重要情報を抽出し、複雑な問い合わせに対して文脈に沿った回答を生成します。
過去データに基づく予測モデルで、トレンドや行動を先読みします。
すべてのデータソースを接続し、事業全体を一元的かつ実行可能な形で把握できます。
企業レベルの暗号化と細かなアクセス制御でデータを保護します。
柔軟な設定オプションにより、プラットフォームを自社要件に合わせて調整できます。
“NextBrain's AutoML platform transformed how we approach data analysis. The no-code interface made AI accessible to our entire team.”

James Dixon
Chief Digital Officer at Atomic 212
“We've seen remarkable improvements in our marketing mix modeling with NextBrain. The insights are actionable and accurate.”

Xavier Romero
CEO at McCann Costa Rica
“The predictive analytics capabilities of NextBrain have given us a competitive edge in understanding customer behavior.”

Andrea Atzori
Co-Founder at Ambire
“NextBrain's workflow automation has streamlined our data pipeline. What took days now takes hours.”

Mike Barr
Director at IQCodex