
デジタルマーケティングとブランド戦略は、進化するトレンドや消費者行動の中でマーケターやストラテジストにとって重要な課題を提示します。成功は、適切なオーディエンスに関連するコンテンツを届け、コストを最適化することに依存しています。しかし、すべてのブランドが意思決定を支えるための十分なデータアクセスを持っているわけではありません。ここで、合成データ生成が重要な役割を果たし、限られたサンプルを増強し、有益なインサイトを抽出します。
デジタルマーケティングにおけるデータの役割
データはデジタルマーケティングを強化し、ブランドがデータ駆動の意思決定を行い、戦略を最適化できるようにします。しかし、急速に変化する状況で詳細なデータを収集することは課題を伴います。マーケターはしばしば統計的に有意でない小規模または中規模のデータセットを扱うため、正確なキャンペーンの成功予測や広告支出の飽和点の特定が妨げられます。
表形式の合成データ:その潜在能力を解き放つ
合成データ生成は画像やテキスト分野で注目を集めていますが、表形式データへの応用はしばしば見落とされています。行と列で構成された表形式の合成データは、デジタルマーケターや戦略家にとって膨大な潜在能力を持っています。最先端の機械学習技術である生成的敵対ネットワーク(GAN)を活用することで、合成データはデータセットを拡張し、「解像度」を向上させ、追加の洞察を明らかにします。
生成的敵対ネットワーク(GAN):合成データ生成を強化する
GANは、生成器と識別器という2つのニューラルネットワークが互いに競い合う強力な機械学習の革新です。生成器は入力データに統計的に類似した新しいデータサンプルを生成し、識別器は実データと合成データを区別します。この敵対的なゲームがトレーニングを推進し、元のデータセットに似た高品質な合成データを生成します。
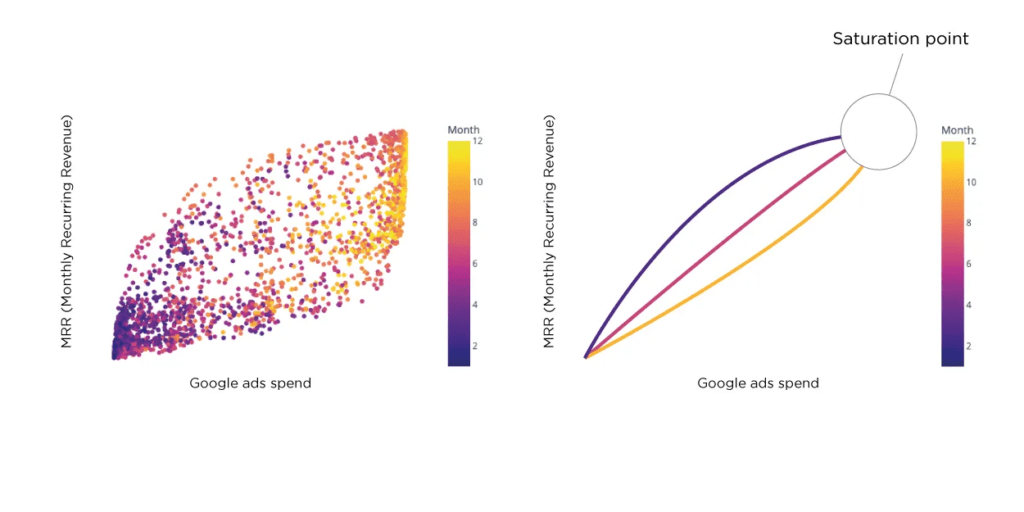
デジタルマーケティングにおける飽和点の理解
飽和点はデジタルマーケティングにおける重要な要素であり、過剰な広告支出からの収益の減少を防ぎます。広告のS字曲線は、支出と売上、収益、または市場シェアへの影響との関係を示しています。あるポイントを超えると、支出を増やしても比例したリターンは得られません。飽和点を正確に推定することは、特に限られたデータで困難です。合成データは、分析のためにより大きなデータセットを提供し、より正確な予測を可能にすることでこれに対処します。
実用的なユースケース:合成データの活用
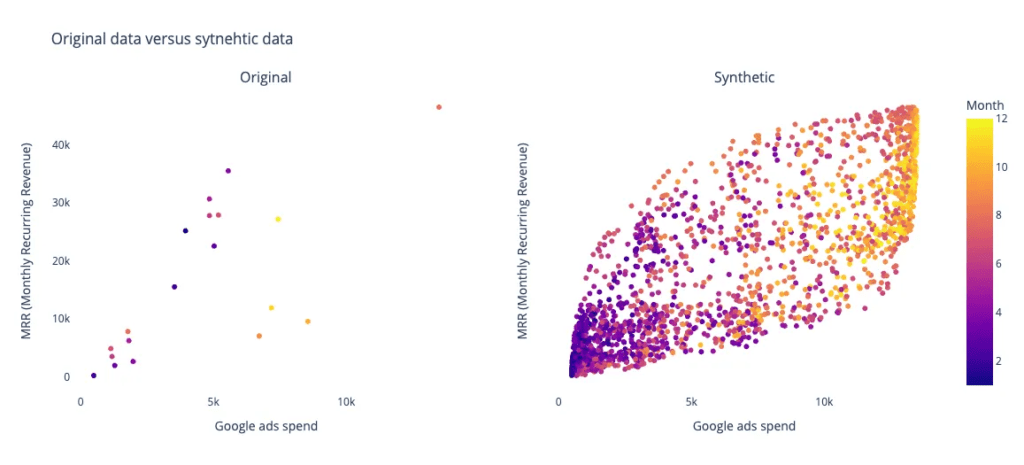
2年前に立ち上げられた新しいブランドを考えてみましょう。限られたデータでさまざまな広告キャンペーンを展開しています。彼らが飽和点に達したかどうかを判断し、次の戦略的ステップを計画することは重要です。元のデータから合成データセットを生成することで、サンプルサイズを拡大し、飽和点やその他の重要な指標に関する洞察を提供します。
オープンソースのPythonライブラリを使用して nbsynthetic NextBrain.aiチームによって、元のデータセットから合成データが生成されます。2000サンプルの合成データセットが作成され、元のデータと合成データの視覚的比較が行われます。さらに、Random Forest Regressorのような機械学習モデルが両方のデータセットで訓練され、月間定期収益(MRR)などの重要な指標を予測します。結果(以下の図)は、合成データで訓練されたモデルが、元のサンプルサイズの小さいデータで訓練されたモデルと比較して、より高い安定性と改善された予測精度を達成していることを示しています。
╔═══════════════╗
結果
╚═══════════════╝
元データ
-------------
クロスバリデーションなしのスコア = 0.32
クロスバリデーションによるスコア = [ 0.19254948 -7.0973158 0.1455913 0.18710539 -0.14113018]
合成データ
--------------
クロスバリデーションなしのスコア = 0.80
クロスバリデーションによるスコア = [0.8009446 0.81271862 0.79139598 0.81252436 0.83137774]
合成データでトレーニングされたアルゴリズムと元のデータでテスト
-------------------------------------------------------------------
クロスバリデーション予測によるスコア = 0.71
この記事はもともとTowards Data Scienceに掲載されました。元の記事を見つけることができます ここ.

 +34 910 054 348
+34 910 054 348 +44 (0) 7903 493 317
+44 (0) 7903 493 317