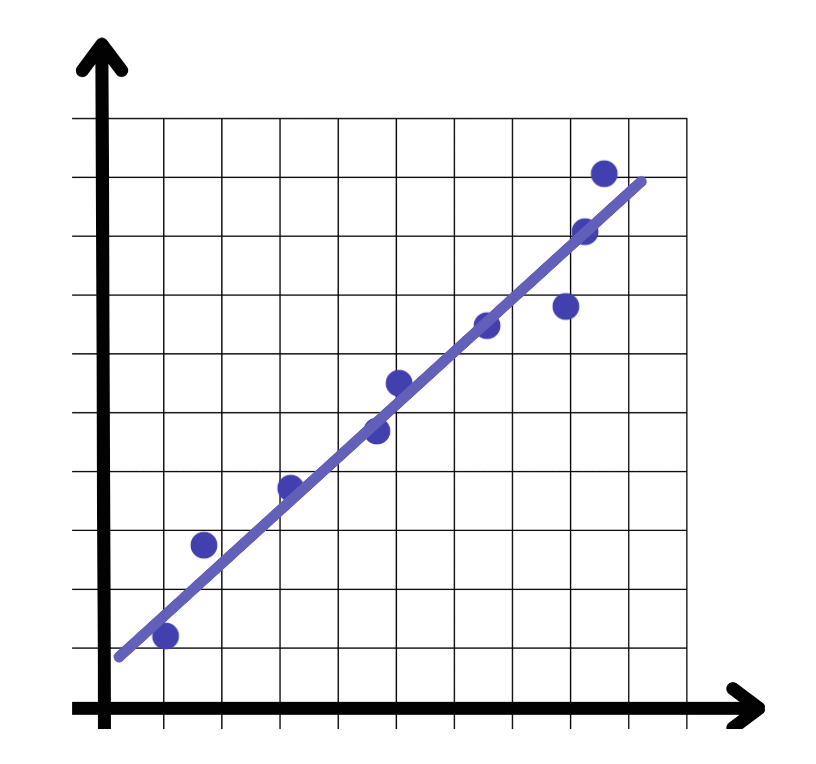
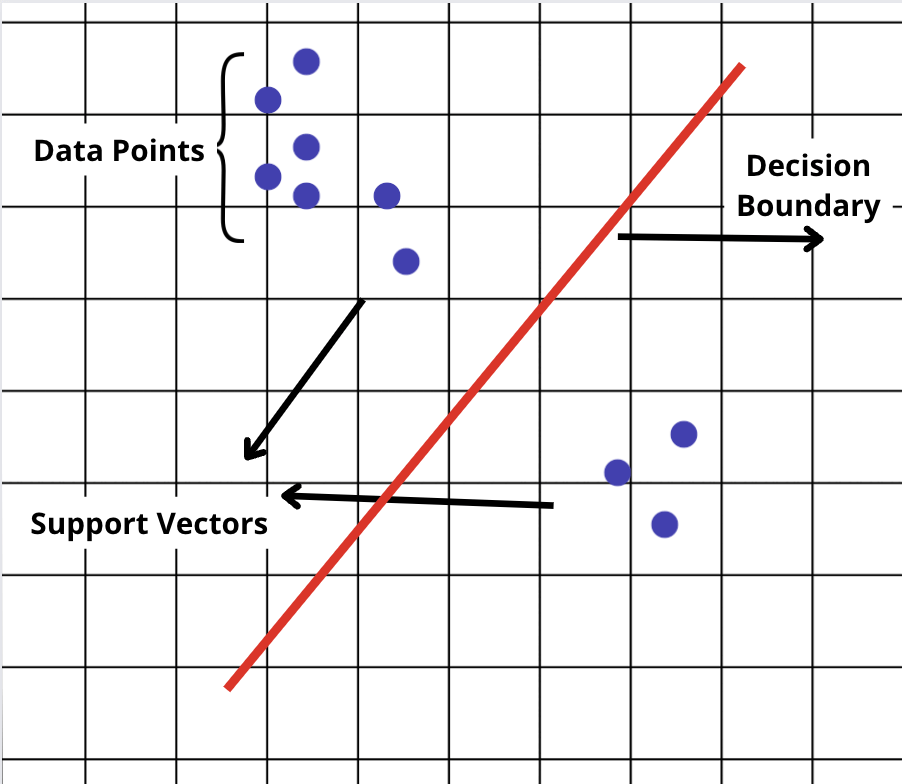
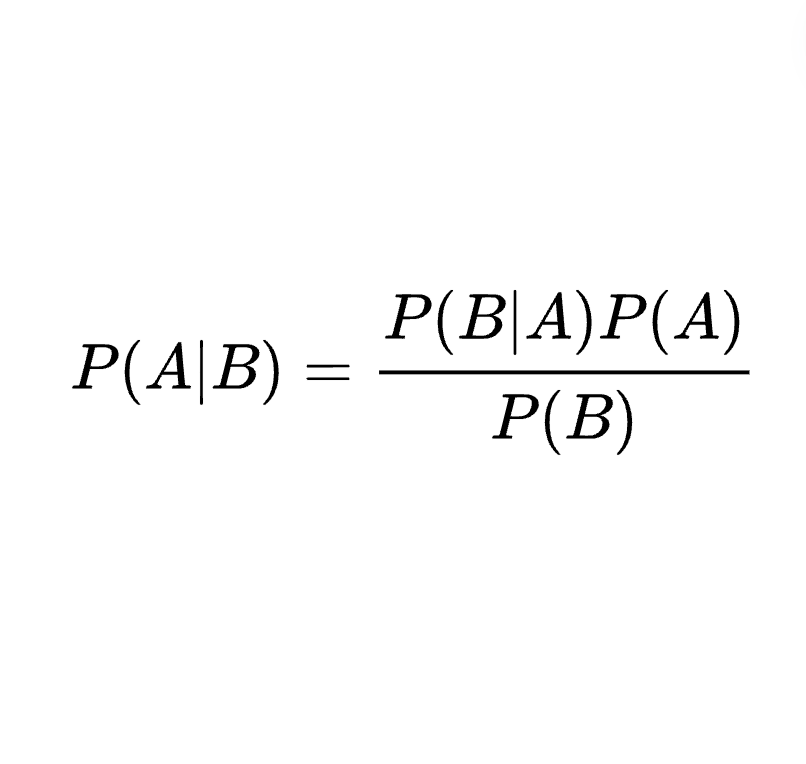
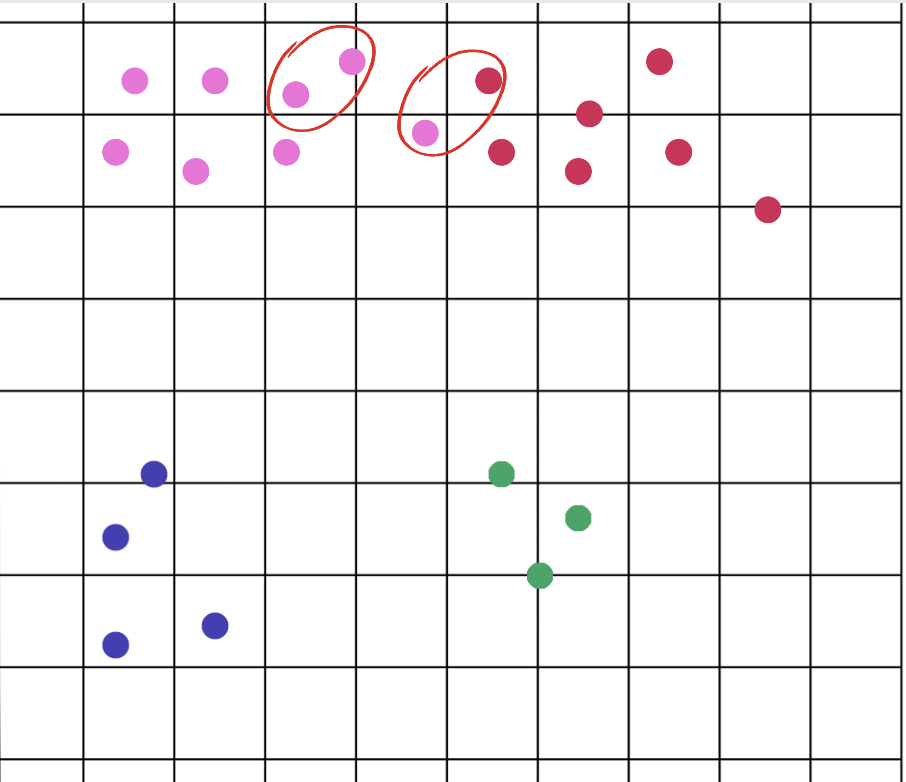




Nuestra misión es hacer de NextBrain un espacio en el que los seres humanos trabajen junto con los algoritmos más avanzados para ofrecer una visión superior de los datos que cambie las reglas del juego. Aprendizaje automático sin código
Oficinas
Madrid
Paseo de la Castellana, n.º 210, 5º-8
28046 Madrid, España
Número de teléfono:  +34 910 054 348
+34 910 054 348
London
122 Leadenhall Street, London
Número de teléfono:  +44 (0) 7903 493 317
+44 (0) 7903 493 317
Horas de apertura (CET)
Lunes—Jueves: 8:00AM–5:30PM
Viernes: 8:00AM–2:00PM
EMEA, América
Soporte de chat en vivo