Inteligencia de modelos
01
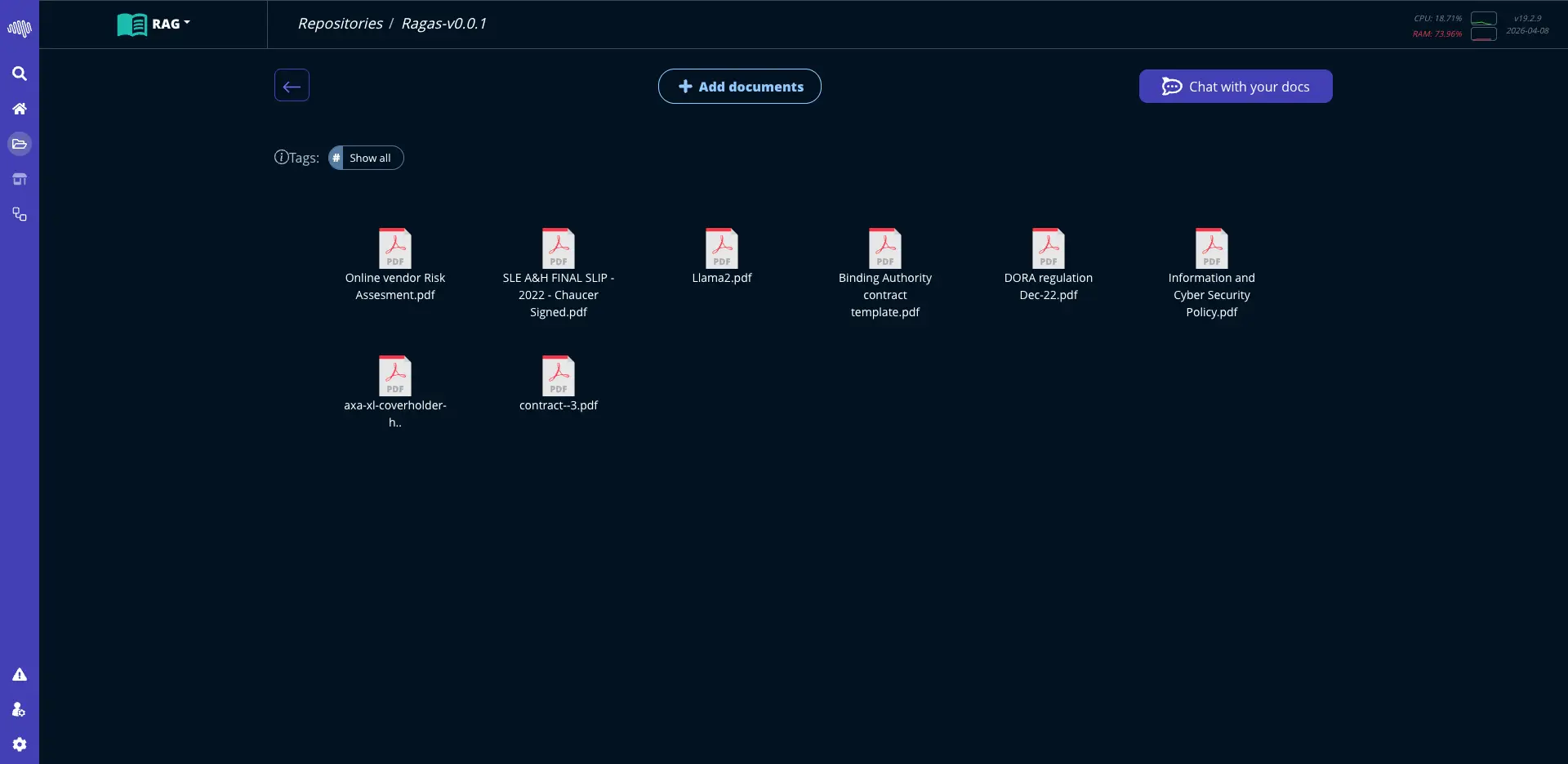
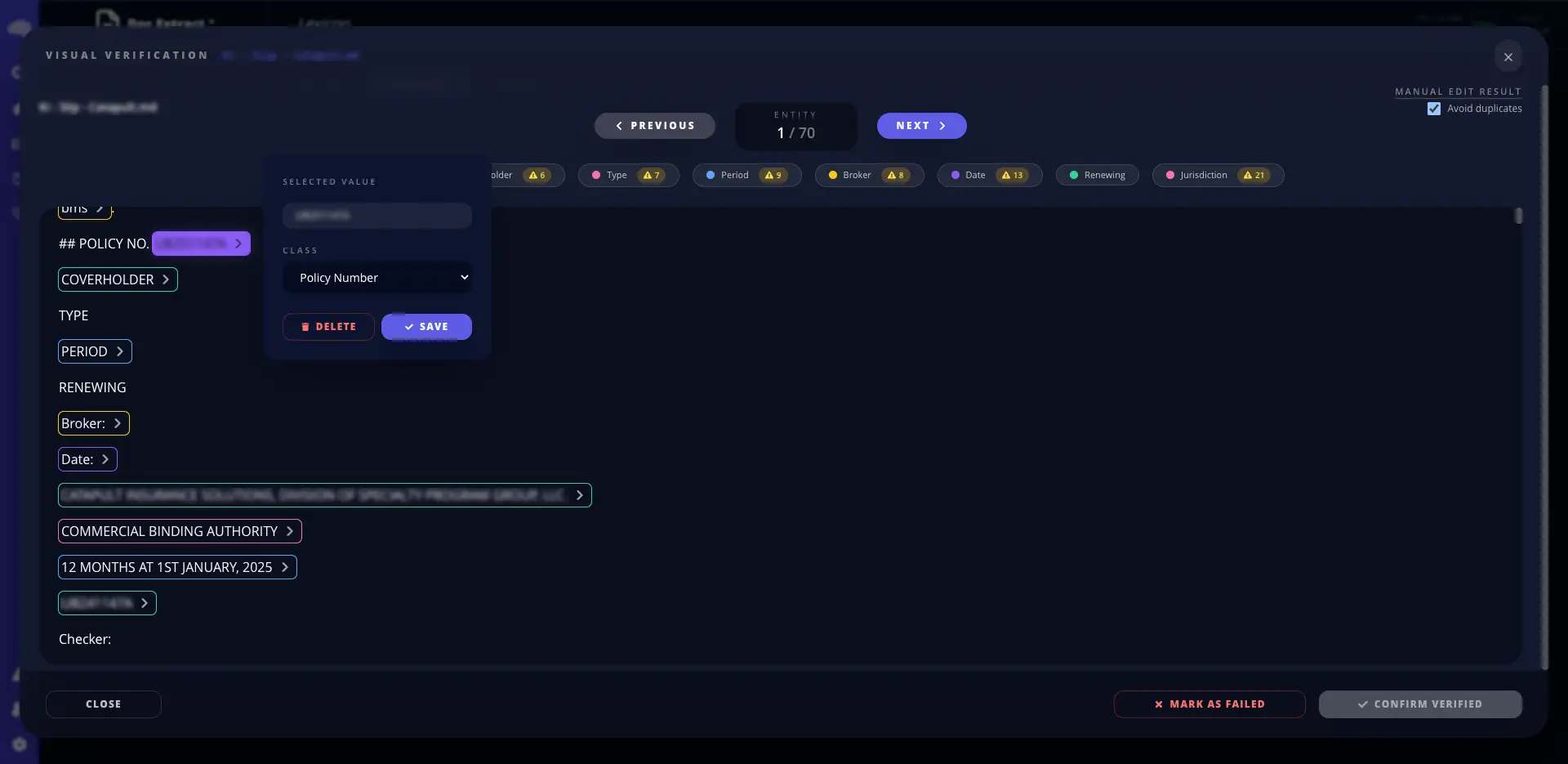
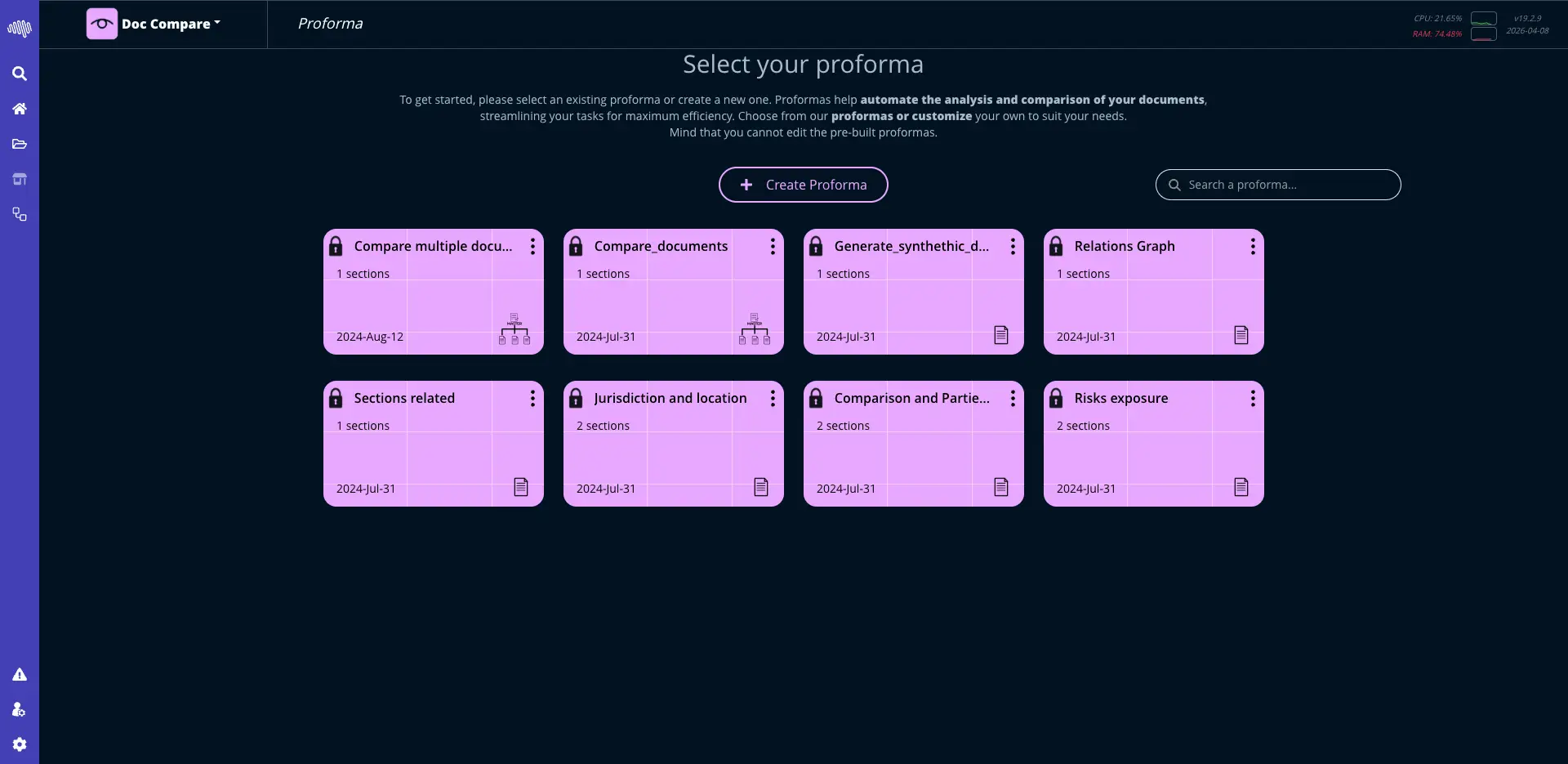
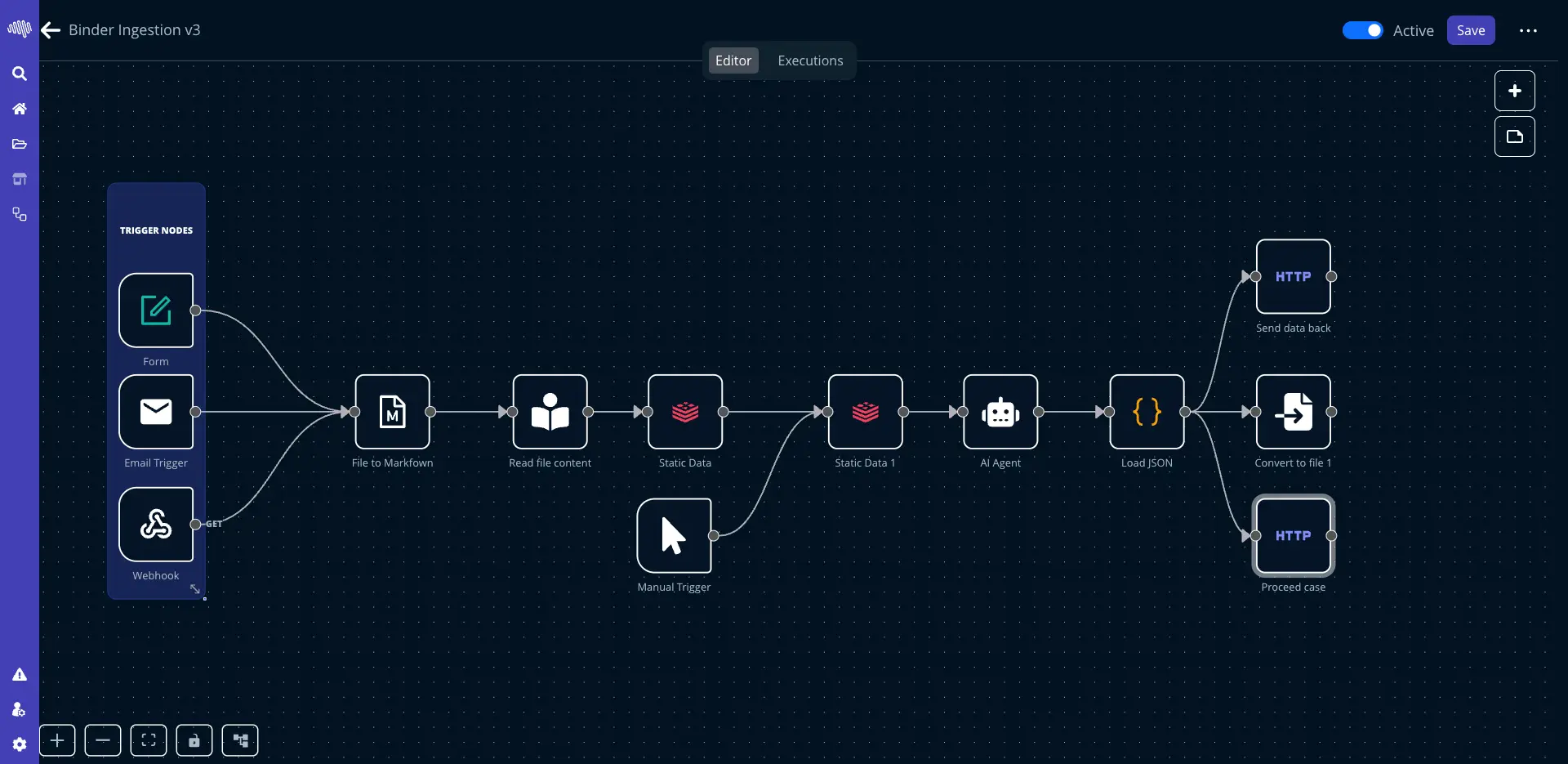
AutoML: Machine Learning
Aprovecha modelos avanzados de IA para extraer insights, generar predicciones y automatizar la toma de decisiones.
Ciclos de modelo mas rapidos
10x
mas velocidad de experimentacion
Forecasting y anomalias Entrenamiento y despliegue low-code Predicciones listas para negocio
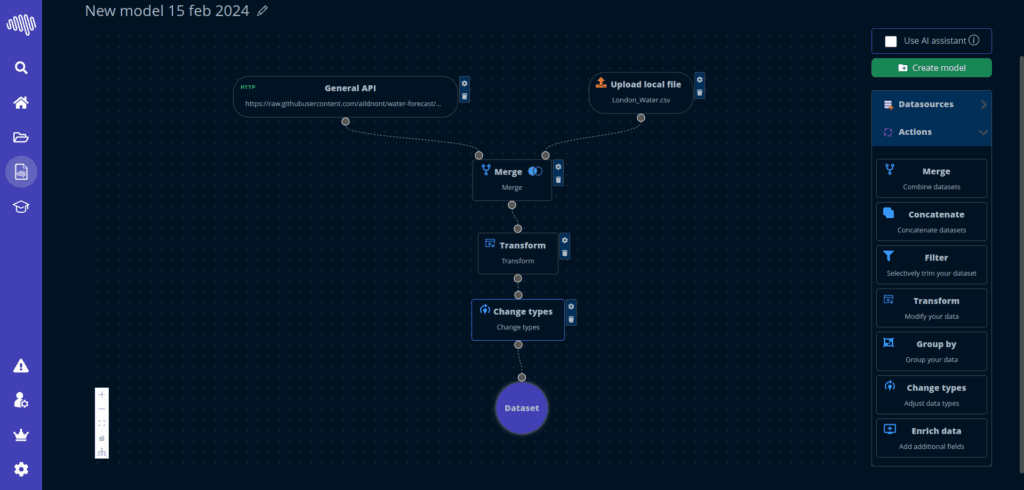
Listo para empresa
Interfaces estructuradas con un camino claro desde la configuracion hasta el despliegue.