No-Code AutoML-Tools Benchmark
NextBrain ist die führende No-Code AutoML-Plattform auf dem Markt, und das aus gutem Grund. Wir haben unsere Plattform im Vergleich zu unseren Wettbewerbern getestet, indem wir dasselbe Dataset und die gleichen Standardtrainingsbedingungen verwendet haben.
Die Ergebnisse sprechen für sich – NextBrain übertrifft konstant die Konkurrenz in Bezug auf Modellgenauigkeit, Trainingszeit und Kosten.Wir sind bestrebt, unseren Nutzern die bestmöglichen Werkzeuge und Ressourcen zur Verfügung zu stellen, um ihnen zum Erfolg zu verhelfen, und unser Performance-Benchmarking ist nur eine Möglichkeit, wie wir unser Engagement für Exzellenz unter Beweis stellen.
Wählen Sie NextBrain zwischen anderen Tools (Azure Machine Learning, Amazon SageMaker, BigML) und erleben Sie die beste No-Code AutoML-Leistung.

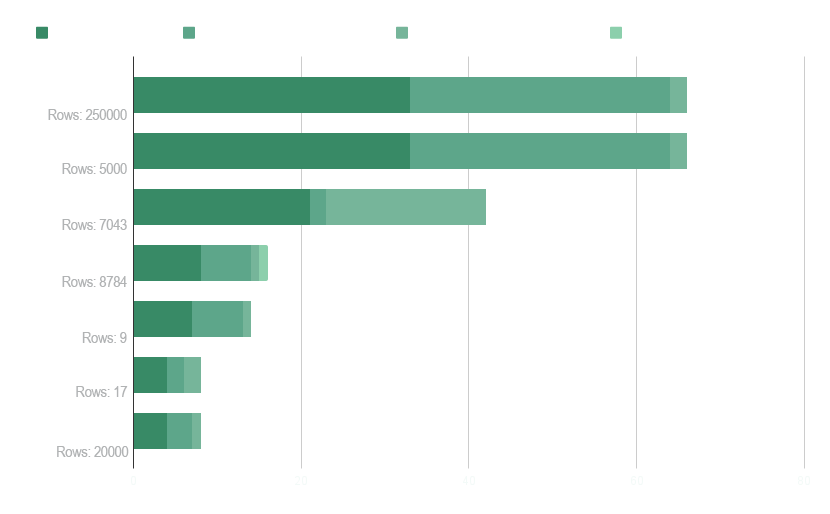
Datensatz
In unseren Leistungsevaluierungen haben wir Datensätze mit unterschiedlichen Anzahl an Zeilen und Spalten für binäre Klassifikation, Mehrklassenklassifikation und multivariate Regressionsprobleme ausgewählt.
Wir haben auch spezielle Datensätze mit nur wenigen Zeilen verwendet und die Modelle mit synthetischen Daten trainiert, die mit NextBrain aus originalen Datenproben generiert wurden.
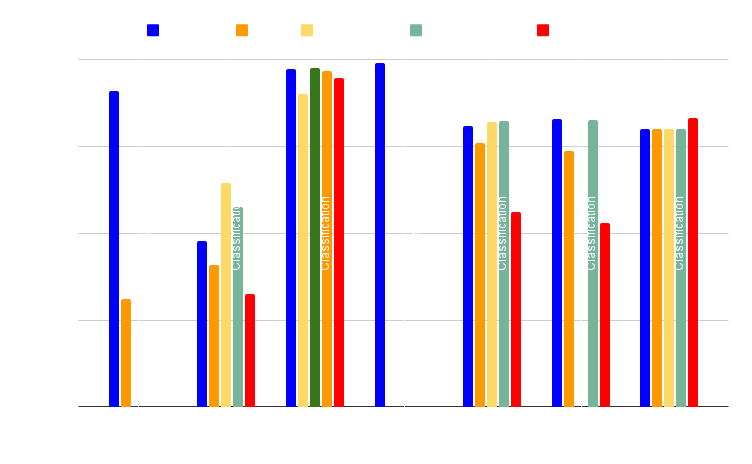
Genauigkeitsbenchmark
In unseren Leistungsevaluierungen haben wir Datensätze mit unterschiedlichen Anzahl an Zeilen und Spalten für binäre Klassifikation, Mehrklassenklassifikation und multivariate Regressionsprobleme ausgewählt.
Wir haben auch spezielle Datensätze mit nur wenigen Zeilen verwendet und die Modelle mit synthetischen Daten trainiert, die mit NextBrain aus originalen Datenproben generiert wurden.
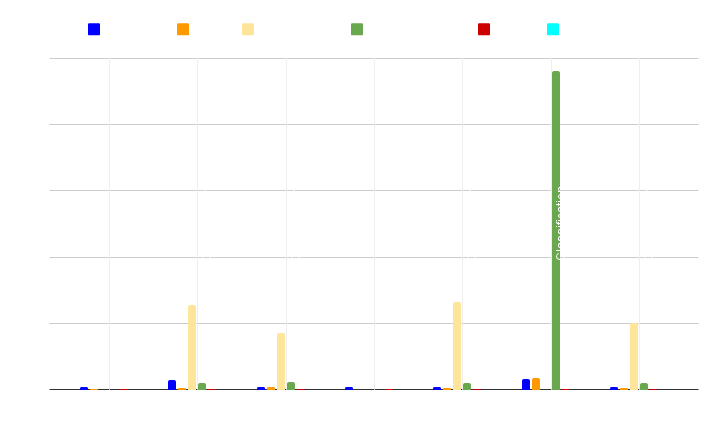
Trainingszeit-Benchmark
In unseren Leistungsevaluierungen haben wir Datensätze mit unterschiedlichen Anzahl an Zeilen und Spalten für binäre Klassifikation, Mehrklassenklassifikation und multivariate Regressionsprobleme ausgewählt.
Wir haben auch spezielle Datensätze mit nur wenigen Zeilen verwendet und die Modelle mit synthetischen Daten trainiert, die mit NextBrain aus originalen Datenproben generiert wurden.
Merkmalsvergleich

- End-to-End-Tool: Der Tool-Anbieter kümmert sich um alle Software- und Hardwarebedürfnisse, einschließlich Installation, Integration und Einrichtung.
- Web-App: Es ist nicht erforderlich, dieses Tool herunterzuladen oder zu installieren, da es als Webanwendung verfügbar ist.
- Spreadsheet-Plugin: Die Anwendung ist als Google Sheets Add-on im GS-Marktplatz verfügbar.
- Bereitstellung auf dem Benutzer-Server: Die Webanwendung kann auf einem benutzerdefinierten Server kopiert werden, um Sicherheitsanforderungen zu erfüllen.
- API-Dienste / SDK: API-Dienste ermöglichen es Benutzern, auf die Funktionalität und Daten des Tools zuzugreifen. Benutzer profitieren von ihrer Flexibilität, Integration, Innovation und Zusammenarbeit.
- Datenbankverbindung: Ein SQL-Datenbankconnector ermöglicht die Integration und Manipulation einer SQL-Datenbank aus anderen Systemen und Anwendungen und bietet Vorteile in Bezug auf Leistung, Skalierbarkeit, Sicherheit und Benutzerfreundlichkeit.
- Marketing-API (Dataslayer.ai): Connector zu Dataslayer.ai, wo mehr als 40 verfügbare Connectors für Marketingdaten vorhanden sind.
- Automatische Datenvorbereitung: Die Anwendung führt sowohl grundlegende als auch fortgeschrittene Datenvorbereitung und Feature Engineering durch, bevor ein Model trainiert wird, um zuverlässigere Erkenntnisse zu gewinnen.
- Generierung synthetischer Daten: Generierung synthetischer Daten, um größere Stichprobendatensätze zu erhalten und die Qualität der Modelle zu verbessern. Ist auch nützlich für die Datenanonymisierung.
- Anpassbare Modelle: Optionen wie zu verwendender Algorithmus und dessen Feineinstellung sind als erweiterte Optionen verfügbar.
- Interaktive Dashboards: Werkzeug zur Visualisierung und zum Teilen von Daten und Erkenntnissen aus Machine Learning Modellen.
Datensatz, den wir verwenden
ROI – Herunterladen
Der Return on Investment (ROI) ist eine wichtige Kennzahl, die verwendet wird, um die Effektivität einer Marketingkampagne zu bewerten. Er wird berechnet, indem der Nettogewinn, den eine Kampagne generiert, durch die Gesamtkosten der Kampagne geteilt wird und wird normalerweise als Prozentsatz ausgedrückt. ROI wird als wichtige Kennzahl für Marketingkampagnen angesehen, da er eine Möglichkeit bietet, die Rentabilität einer Kampagne zu messen und sie mit anderen Kampagnen oder Investitionen zu vergleichen. Dies kann Marketingfachleuten helfen, zu bestimmen, welche Kampagnen am effektivsten sind und wo sie ihre Ressourcen in Zukunft zuweisen sollten. Darüber hinaus ist ROI wichtig, da er hilft, Marketinganstrengungen mit den Unternehmenszielen in Einklang zu bringen. Indem sie sich auf Kampagnen konzentrieren, die einen hohen ROI generieren, können Marketingfachleute sicherstellen, dass ihre Bemühungen zum finanziellen Gesamterfolg des Unternehmens beitragen. Dies ist besonders wichtig in der heutigen Geschäftswelt, in der Unternehmen unter zunehmendem Druck stehen, den Wert ihrer Marketingausgaben nachzuweisen.
![]() Ziel: MRR (Monatlich wiederkehrende Einnahmen)
Ziel: MRR (Monatlich wiederkehrende Einnahmen)
 Datenquelle: Dataslayer.ai
Datenquelle: Dataslayer.ai
 Lizenz: Datendateien © Dataslayer.ai
Lizenz: Datendateien © Dataslayer.ai
Wald LiDAR – Herunterladen
Die Technologie der Lichtdetektion und -entfernung (LIDAR) ist zu einem wesentlichen Werkzeug für den Umweltschutz geworden. Lidar ist eine Technologie, die einen Laser verwendet, um ein Objekt oder eine Oberfläche zu zielen und die Rückkehr des reflektierten Lichts zum Empfänger zu zeitlich zu erfassen. Sie kann beispielsweise verwendet werden, um computerisierte 3D-Darstellungen von Bereichen auf der Erdoberfläche zu erzeugen. Infolgedessen haben Ökologen und Biologen in dieser Technologie den besten Partner für Erkennungs-, Klassifizierungs- und Naturschutzaktivitäten gefunden. Diese Technologie erfordert jedoch erhebliche Rechenressourcen, um die Millionen von Punkten zu verarbeiten, die für einen einzelnen Quadratmeter Analyse gewonnen werden. Alle diese Punkte müssen klassifiziert und segmentiert werden, und es gibt verschiedene mathematische und rechnerische Methoden, die verwendet werden können, um all diese Daten zu verarbeiten und lesbare sowie interpretierbare Ergebnisse zu liefern. Dieses Datenset enthält eine LIDAR-Darstellung von drei Bäumen. Jeder Punkt wird durch seine X-, Y- und Z-Koordinaten dargestellt. Daher hat das Datenset nur drei Eingangsvariablen (x,y,z) und ein Ziel (Baum).
![]() Ziel: Baum
Ziel: Baum
Datenquelle: CIFOR und Wageningen Universität
Lizenz: Daten Dateien © CIFOR und Wageningen Universität
Referenz:
Gonzalez de Tanago, J, Lau, A, Bartholomeus, H, et al. (2018). Schätzung der oberirdischen Biomasse großer tropischer Bäume mit terrestrischem LiDAR. Methods Ecol Evol. 9: 223–234. https://doi.org/10.1111/2041-210X.12904
Higgs-Boson – Herunterladen
Dieser Datensatz enthält eine Benchmark-Aufgabe für Machine-Learning-Klassifikationsalgorithmen, die darauf ausgelegt ist, zwischen einem Signalprozess, bei dem neue theoretische Higgs-Bosonen produziert werden, und einem Hintergrundprozess mit identischen Zerfallsprodukten, aber unterschiedlichen kinematischen Merkmalen zu unterscheiden (Baldi P. et al, 2014). Der Datensatz enthält die folgenden Spalten: die Zielspalten (“Label”) ist das Klassenlabel (1 für Signal, 0 für Hintergrund). Es gibt 28 Merkmale (21 Low-Level-Merkmale und dann 7 High-Level-Merkmale): lepton pT, lepton eta, lepton phi, fehlende Energiedimension, fehlende Energie phi, jet 1 pt, jet 1 eta, jet 1 phi, jet 1 b-tag, jet 2 pt, jet 2 eta, jet 2 phi, jet 2 b-tag, jet 3 pt, jet 3 eta, jet 3 phi, jet 3 b-tag, jet 4 pt, jet 4 eta, jet 4 phi, jet 4 b-tag, m_jj, m_jjj, m_lv, m_jlv, m_bb, m_wbb, m_wwbb. Die detaillierte Beschreibung dieser Spalten ist in Baldi P. et al. 2014 zu finden.
![]() Ziel: Etikett
Ziel: Etikett
Datenquelle: https://archive.ics.uci.edu/ml/datasets/higgs
Lizenz: Daten Dateien © Daniel Whiteson
Referenz:
Baldi, P., Sadowski, P., & Whiteson, D. (2014). Suche nach exotischen Teilchen in der Hochenergiephysik mit Deep Learning. Nature Communications, 5(1), 1-9.
Physik universelle Gesetze – Herunterladen
Maschinenlernalgorithmen werden derzeit verwendet, um die Entdeckung von physikalischen Prinzipien und Governing Equations basierend auf Daten zu automatisieren, anstatt komplexe Gleichungssysteme zu lösen. Indem wir das klassische Problem der Modellierung fallender Objekte unterschiedlicher Größen und Massen ansprechen, können wir eine Reihe von schwierigen Problemen identifizieren, die von modernen datengestützten Methoden für die automatisierte Physikentdeckung verwaltet werden müssen. Wir zielen darauf ab, das klassische Problem der Modellierung fallender Objekte unterschiedlicher Größen und Massen für die automatisierte Physikentdeckung anzugehen. Theoretische Forschung zu Fluidkräften auf einer idealisierten Kugel hat zu einer umfangreichen Geschichte der wissenschaftlichen Forschung geführt. Neben der Schwerkraft und dem Widerstand kann die Trajektorie eines Balls durch seinen Spin über die Magnus-Kraft oder Auftriebskraft, die orthogonal zum Widerstand wirkt, verändert werden. Weitere Variablen, die die von einem fallenden Ball erzeugten Kräfte beeinflussen können, sind Lufttemperatur, Wind, Höhe und die Form der Balloberfläche (de Silva et al. 2020). Die Datenquelle ist der Artikel “Entdeckung der Physik aus Daten: Universelle Gesetze und Diskrepanzen (de Silva et al. 2020). Der Datensatz umfasst Beobachtungen für neun verschiedene Arten von Bällen: einen Golfball, einen Baseball, einen Tennisball, einen blauen Basketball, einen grünen Basketball, einen Whiff-Ball, einen gelben Whiffle-Ball und einen orangefarbenen Whiffle-Ball.
![]() Ziel: Landungszeit
Ziel: Landungszeit
Datenquelle: https://www.frontiersin.org/files/Articles/479363/frai-03-00025-HTML/image_m/frai-03-00025-t001.jpg
Lizenz: Daten © Silva, B. M., Higdon, D. M., Brunton, S. L., Kutz, J. N
Referenz:
de Silva, B. M., Higdon, D. M., Brunton, S. L., & Kutz, J. N. (2020). Entdeckung der Physik aus Daten: Universelle Gesetze und Diskrepanzen. Frontiers in Artificial Intelligence, 3, 25. https://doi.org/10.3389/frai.2020.00025
Telekommunikationskündigung – Herunterladen
Kundenabwanderung, auch bekannt als Kundenattrition, bezieht sich auf den Prozentsatz der Kunden, die aufhören, die Produkte oder Dienstleistungen eines Unternehmens über einen bestimmten Zeitraum hinweg zu nutzen. Es ist eine wichtige Kennzahl für ein Telekommunikationsunternehmen, da die Kundenabwanderung erhebliche finanzielle Auswirkungen haben kann. Telekommunikationsunternehmen haben typischerweise hohe Fixkosten, wie die Kosten für den Aufbau und die Wartung von Netzwerken und Infrastrukturen, und diese Kosten müssen über eine große Kundenbasis verteilt werden, um finanziell tragfähig zu sein. Wenn die Rate der Kundenabwanderung hoch ist, kann dies zu einem Rückgang der Gesamtzahl der Kunden führen, was es für das Unternehmen schwieriger machen kann, seine Fixkosten zu decken. Dies kann letztendlich zu einem Rückgang der Rentabilität führen. Durch die Verfolgung der Kundenabwanderungsrate kann ein Telekommunikationsunternehmen Trends und Muster im Kundenverhalten identifizieren und Maßnahmen ergreifen, um die Bindung zu verbessern und die Abwanderungsrate zu senken. Dies könnte die Bereitstellung wettbewerbsfähigerer Preise, die Verbesserung des Kundenservice oder die Einführung neuer Produkte und Dienstleistungen umfassen, die für Kunden attraktiver sind.
![]() Ziel: Abwanderung
Ziel: Abwanderung
Datenquelle: Datensatz angepasst von der IBM Business Analytics Community (https://community.ibm.com/community/user/businessanalytics/blogs/steven-macko/2019/07/11/telco-customer-churn-1113).
Lizenz: Datendateien © IBM
Wetterdaten – Herunterladen
Die Vorhersage des Wetters ist aus verschiedenen Gründen für Gemeinschaften wichtig. Zunächst einmal können genaue Wettervorhersagen den Menschen helfen, sicher zu bleiben, indem sie ihnen ermöglichen, sich auf extreme Wetterereignisse wie Hurrikane, Überschwemmungen und Schneestürme vorzubereiten. Wenn eine Gemeinschaft beispielsweise weiß, dass ein großer Sturm bevorsteht, kann sie Schritte unternehmen, um ihre Häuser abzusichern, gegebenenfalls zu evakuieren und Vorräte anzulegen. Neben Sicherheitsbedenken sind genaue Wettervorhersagen auch aus wirtschaftlichen Gründen wichtig. Viele Unternehmen und Branchen sind vom Wetter betroffen und sind auf genaue Vorhersagen angewiesen, um ihre Abläufe zu planen und informierte Entscheidungen zu treffen. Beispielsweise müssen Landwirte wissen, wie das Wetter sein wird, um zu entscheiden, wann sie ihre Ernte pflanzen und ernten, und Bauunternehmen müssen wissen, ob es heiß oder kalt sein wird, um ihre Arbeitspläne zu erstellen. Schließlich sind genaue Wettervorhersagen wichtig für das tägliche Leben. Sie ermöglichen es den Menschen, ihre Aktivitäten im Freien zu planen und Entscheidungen darüber zu treffen, was sie tragen und wie sie reisen. Sie können auch die Stimmung und das Wohlbefinden der Menschen beeinflussen, da schlechtes Wetter die Menschen niedergeschlagen machen oder sogar ihre psychische Gesundheit beeinträchtigen kann.
![]() Ziel: Wetter
Ziel: Wetter
Datenquelle: Adapted von historischen stündlichen Wetterdaten 2012-2017 (https://www.kaggle.com/datasets/selfishgene/historical-hourly-weather-data?select=pressure.csv).
Lizenz: Dieser Datensatz wird unter der Open Database License zur Verfügung gestellt: http://opendatacommons.org/licenses/odbl/1.0/. Alle Rechte an einzelnen Inhalten der Datenbank sind unter der Datenbank-Inhaltslizenz lizenziert: http://opendatacommons.org/licenses/dbcl/1.0/

 +34 910 054 348
+34 910 054 348 +44 (0) 7903 493 317
+44 (0) 7903 493 317