Die Reise von Retrieval Augmented Generation (RAG) zu RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) markiert einen bedeutenden Fortschritt bei der Bewältigung von Herausforderungen wie Halluzinationen und sicher falschen Antworten.
Angetrieben von Ollama und Open-Source-Tools erhöht dieser Entwicklungsweg die Genauigkeit und Benutzerfreundlichkeit von AI.

Verstehen von RAG (Retrieval Augmented Generation)
RAG verbessert die AI-Antworten, indem vortrainierte Modelle mit benutzerspezifischen Daten aus externen Quellen wie JSON, PDFs oder GitHub-Repositories ergänzt werden. Diese Daten werden in Teile umgewandelt, die in einem Vektor-Store gespeichert werden, wodurch AI relevante Informationen abrufen kann, was Halluzinationen und falsche Antworten reduziert.

Fortschritt zu RAG Fusion
RAG Fusion baut auf RAG auf, indem es Multi-Query-Generierung und reziproke Rangfolge integriert. Multi-Query-Generierung umfasst AI, die mehrere Fragen aus der ursprünglichen Anfrage des Benutzers erstellt, was den Abrufprozess verbessert. Die reziproke Rangfolge bewertet dann diese Antworten und stellt sicher, dass die genaueste und relevanteste Antwort bereitgestellt wird.
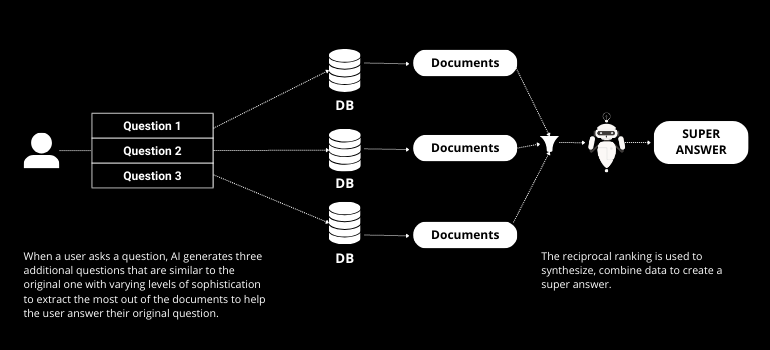
Einführung von RAPTOR (Rekursives Abstraktverarbeiten für baumorganisierten Abruf)
RAPTOR bringt AI-Abruf einen Schritt weiter. Im Gegensatz zu traditionellem RAG organisiert RAPTOR Daten in einer Baumstruktur und fasst sie auf jeder Ebene von unten nach oben zusammen. Diese Methode erfasst einen breiteren Kontext und verbessert die Darstellung großangelegter Diskurse, wodurch die Einschränkungen des Abrufs nur kurzer Textstücke überwunden werden.

Praktische Implementierung mit Ollama und Open-Source-Tools
Mit auf GitHub verfügbaren Tools kann RAPTOR problemlos implementiert werden. Der Prozess umfasst die Umwandlung von Daten in JSON, die Erstellung von Embeddings und die Organisation dieser in einer Baumstruktur, die in einem Vektor-Store gespeichert wird. Ollama bietet die Infrastruktur, um diese Prozesse lokal auszuführen und gewährleistet Privatsphäre und Sicherheit.
Schritt für Schritt: Von RAG zu RAPTOR
- Datenvorbereitung: Datenquellen in JSON umwandeln und in LangChain laden.
- Textaufteilung: Verwenden Sie rekursive oder semantische Chunking, um Text in handhabbare Teile zu unterteilen.
- Erstellung von Embeddings: Generieren Sie Embeddings mit lokalen Modellen, um die Privatsphäre zu gewährleisten.
- Baumorganisation: Erstellen Sie eine Baumstruktur, indem Sie Daten auf jeder Ebene zusammenfassen.
- Speicherung und Abruf: Speichern Sie den Baum in einem Vektor-Store für einen effizienten Abruf.
Vorteile von RAPTOR
Der baumorganisierte Ansatz von RAPTOR bietet mehrere Vorteile:
- Erweiterter Kontext: Erfasst größere Diskursstrukturen und verbessert die Antwortgenauigkeit.
- Effiziente Retrieval: Die Baumstruktur ermöglicht eine schnellere und relevantere Informationsbeschaffung.
- Skalierbarkeit: Eignet sich zur Verarbeitung großer Datensätze mit komplexen Strukturen.
Fazit
Die Evolution von RAG zu RAPTOR stellt einen bedeutenden Sprung in den AI-Retrieval-Fähigkeiten dar. Dieser Fortschritt adressiert zentrale Herausforderungen in den AI-Antworten und macht es zu einem wertvollen Werkzeug für Entwickler und Forscher.
Deshalb ist es entscheidend, informiert und engagiert zu bleiben, während wir diese aufregende Ära durchschreiten. Mit unserer Plattform, NextBrain AI, können Sie die volle Kraft von Language Models nutzen, um Ihre Daten mühelos zu analysieren und strategische Erkenntnisse zu gewinnen. Vereinbaren Sie noch heute Ihre Demo , um zu sehen, was KI aus Ihren Daten enthüllen kann.


 +34 910 054 348
+34 910 054 348 +44 (0) 7903 493 317
+44 (0) 7903 493 317