Le parcours de la Génération Augmentée par Récupération (RAG) à RAPTOR (Traitement Abstractive Récursif pour la Récupération Organisée en Arbre) marque des progrès significatifs dans la résolution de défis tels que les hallucinations et les réponses incorrectes avec confiance.
Propulsé par Ollama et des outils open-source, ce chemin de développement augmente la précision et l'utilisabilité de l'IA.

Comprendre RAG (Génération Augmentée par Récupération)
RAG améliore les réponses de l'IA en complétant les modèles pré-entraînés avec des données spécifiques à l'utilisateur provenant de sources externes comme JSON, PDFs ou dépôts GitHub. Ces données sont transformées en morceaux stockés dans un vecteur store, permettant à l'IA de récupérer des informations pertinentes, réduisant ainsi les hallucinations et les réponses incorrectes.

Passer à RAG Fusion
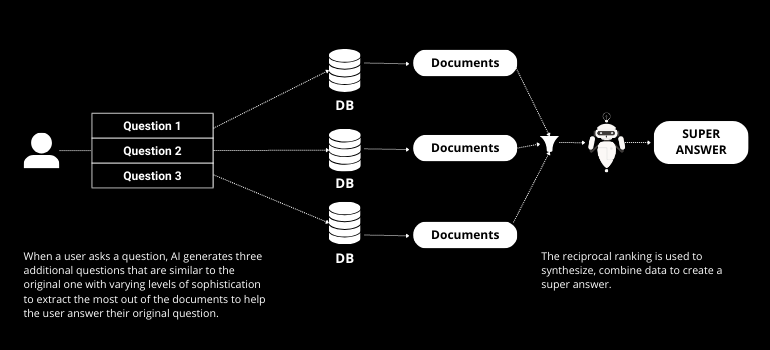
RAG Fusion s'appuie sur RAG en intégrant la génération de requêtes multiples et le classement réciproque. La génération de requêtes multiples implique que l'IA crée plusieurs questions à partir de la requête originale de l'utilisateur, améliorant le processus de récupération. Le classement réciproque classe ensuite ces réponses, garantissant que la réponse la plus précise et pertinente est fournie.
Présentation de RAPTOR (Traitement Abstractive Récursif pour la Récupération Organisée en Arbre)
RAPTOR fait un pas supplémentaire dans la récupération par IA. Contrairement à RAG traditionnel, RAPTOR organise les données dans une structure arborescente, résumant à chaque couche de bas en haut. Cette méthode capture un contexte plus large et améliore la représentation de discours à grande échelle, surmontant les limitations de la récupération de seulement de courts morceaux de texte.

Mise en œuvre pratique avec Ollama et des outils open-source
En utilisant des outils disponibles sur GitHub, RAPTOR peut être implémenté facilement. Le processus implique de convertir des données en JSON, de créer des embeddings et de les organiser dans une structure arborescente stockée dans un vector store. Ollama fournit l'infrastructure pour exécuter ces processus localement, garantissant la confidentialité et la sécurité.
Étape par étape : De RAG à RAPTOR
- Préparation des données: Convertir les sources de données en JSON et les charger dans LangChain.
- Fractionnement du texte: Utiliser des techniques de découpage récursif ou sémantique pour diviser le texte en morceaux gérables.
- Création d'embeddings: Générer des embeddings en utilisant des modèles locaux pour garantir la confidentialité.
- Organisation en arbre: Construire une structure arborescente en résumant les données à chaque couche.
- Stockage et Récupération: Stockez l'arbre dans un vector store pour une récupération efficace.
Avantages de RAPTOR
L'approche organisée par arbre de RAPTOR offre plusieurs avantages :
- Contexte Amélioré: Captures une structure de discours plus large, améliorant l'exactitude des réponses.
- Récupération Efficace: La structure en arbre permet une récupération d'informations plus rapide et plus pertinente.
- Scalabilité: Adapté pour traiter de grands ensembles de données avec des structures complexes.
Conclusion
L'évolution de RAG à RAPTOR marque un saut significatif dans les capacités de récupération de l'IA. Cette progression répond à des défis clés dans les réponses de l'IA, en faisant un outil précieux pour les développeurs et les chercheurs.
Il est donc crucial de rester informé et engagé alors que nous naviguons dans cette ère passionnante. Avec notre plateforme, NextBrain AI, vous pouvez exploiter toute la puissance des language models pour analyser sans effort vos données et obtenir des insights stratégiques. Planifiez votre démonstration aujourd'hui pour voir ce que l'IA peut révéler de vos données.


 +34 910 054 348
+34 910 054 348 +44 (0) 7903 493 317
+44 (0) 7903 493 317