
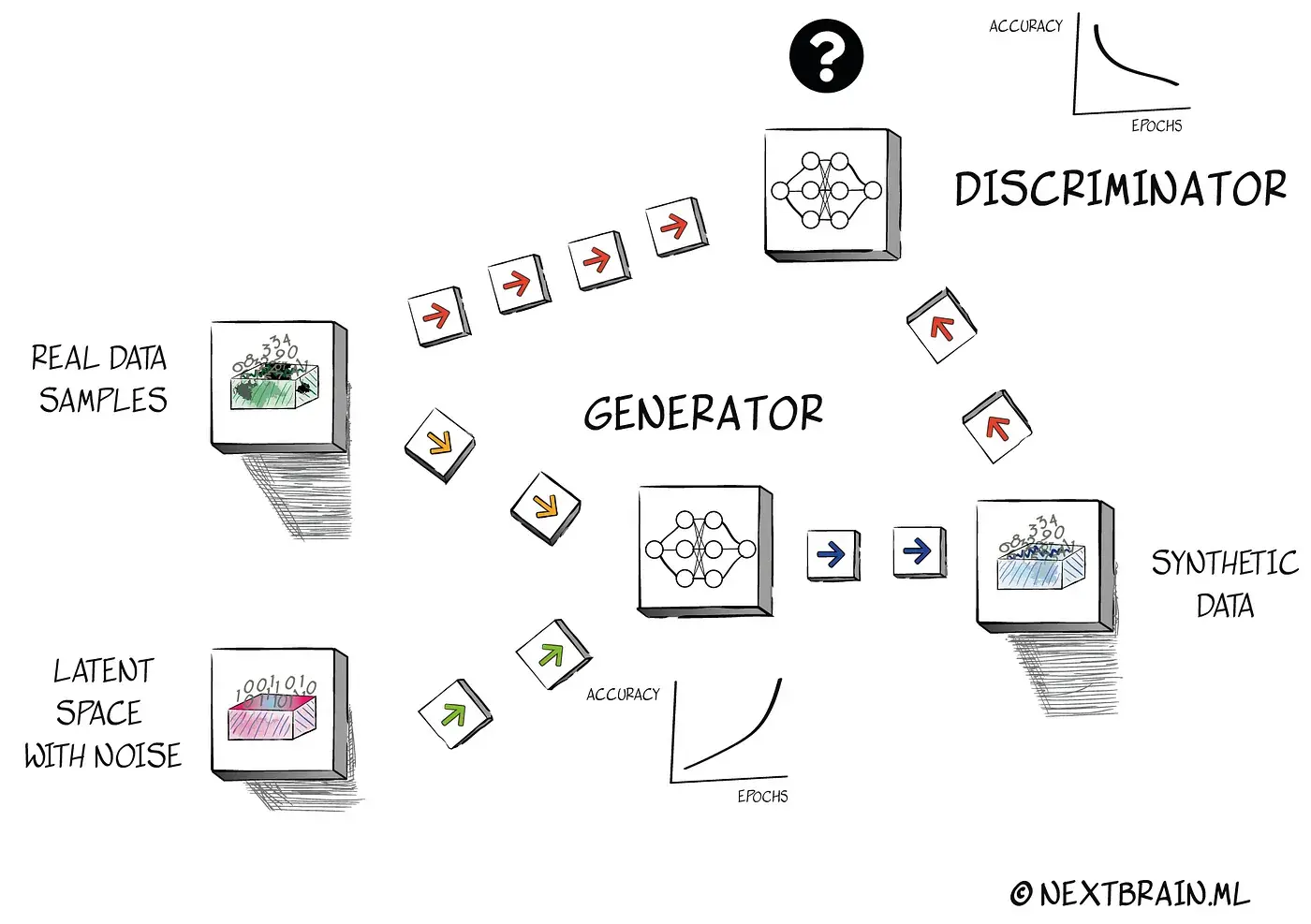
Open-Source-Projekte sind besonders dann wertvoll, wenn sie Transparenz, Lernbarkeit und praktische Erweiterbarkeit zusammenbringen. nbsynthetic ist in diesem Kontext interessant, weil es den Zugang zu synthetischen Daten und modellnahen Workflows verbreitert.
Warum das relevant ist
Open Source hilft Teams dabei:
- Methoden besser nachzuvollziehen;
- Dinge schneller selbst zu testen;
- Werkzeuge an eigene Anforderungen anzupassen;
- Abhaengigkeit von geschlossenen Black-Box-Systemen zu reduzieren.
Fazit
nbsynthetic zeigt, wie Open Source dazu beitragen kann, KI- und Datenarbeit zugaenglicher und kontrollierbarer zu machen.