Intelligence des modeles
01
AutoML : Machine Learning
Exploitez des modeles IA avances pour extraire des insights, produire des previsions et automatiser la prise de decision.
Cycles modele plus rapides
10x
experimentations accelerees
Forecasting et detection d anomalies Entrainement et deploiement low-code Predictions directement utiles au metier
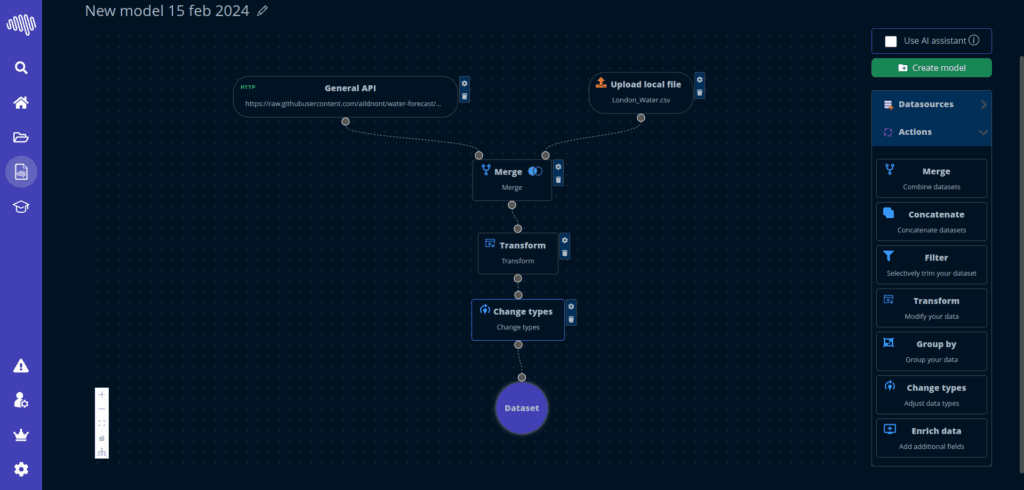
Pret pour l entreprise
Interfaces structurees avec un chemin clair de la configuration au deploiement.